Evolving Voice Agents into Collaborative Partners
Utilizing high-precision recall and low-latency performance to drive interactive experiences across deep conversation archives.


Brief demonstrations frequently obscure the true constraints of AI agents. While retrieval systems function smoothly in sanitized settings with immediate context, the professional world is far more chaotic.
Real-world work is characterized by months of evolving needs, conditional logic, and extensive dialogue logs. Developing "collaborative partners" capable of navigating this complexity entails addressing two specific layers of interaction.
The primary layer consists of a real-time, multi-party participant: An agent that actively monitors and engages in live discussions. Consider a fast-paced, vague team dialogue:
“Forward it by Friday.”
“Apply that to Arjun as well.”
“We can address that following legal review.”
Human teammates naturally identify these ambiguities and clarify:
“To be clear, are we sending the NDA for e-signature by this Friday?”
Replicating this spontaneous clarification is a significant technical hurdle. While firms like Thinking Machine Labs are working to embed this collaborative interactivity directly into the model layer, its real-world efficacy remains to be seen.
The secondary layer is the interactive system of work, which functions as a post-processing engine. After a session concludes, the transcript is analyzed asynchronously to organize memory and establish a precise, low-latency retrieval system.
Developing an agent that can navigate years of operational context requires a fundamental shift: moving away from a focus on search speed and toward an architecture centered on the operational state. The proliferation of high-accuracy small and "flash" models, paired with near-instantaneous speech-to-text and text-to-speech tools like Cartesia, allows interactions with post-processed data to feel remarkably collaborative and human, provided the foundational memory structure is sound. The core objective of this blog is to explore this specific layer of interaction.
RAG architectures and even modern advanced memory architectures frequently fail under the weight of long-term operational demands. These failures stem from viewing memory as a search challenge rather than the continuous maintenance of an active operational state.
Voice agents struggle with a critical trade-off: Providing immediate feedback while maintaining high precision as datasets expand. When a system requires several seconds to navigate a graph, it becomes merely a tool rather than a partner; Conversely, sacrificing accuracy for speed through hallucinations erodes user trust.
To truly master extensive context, we must stop overvaluing raw retrieval speed and begin architecting for the operational state.
Case Study: The Standup Dilemma
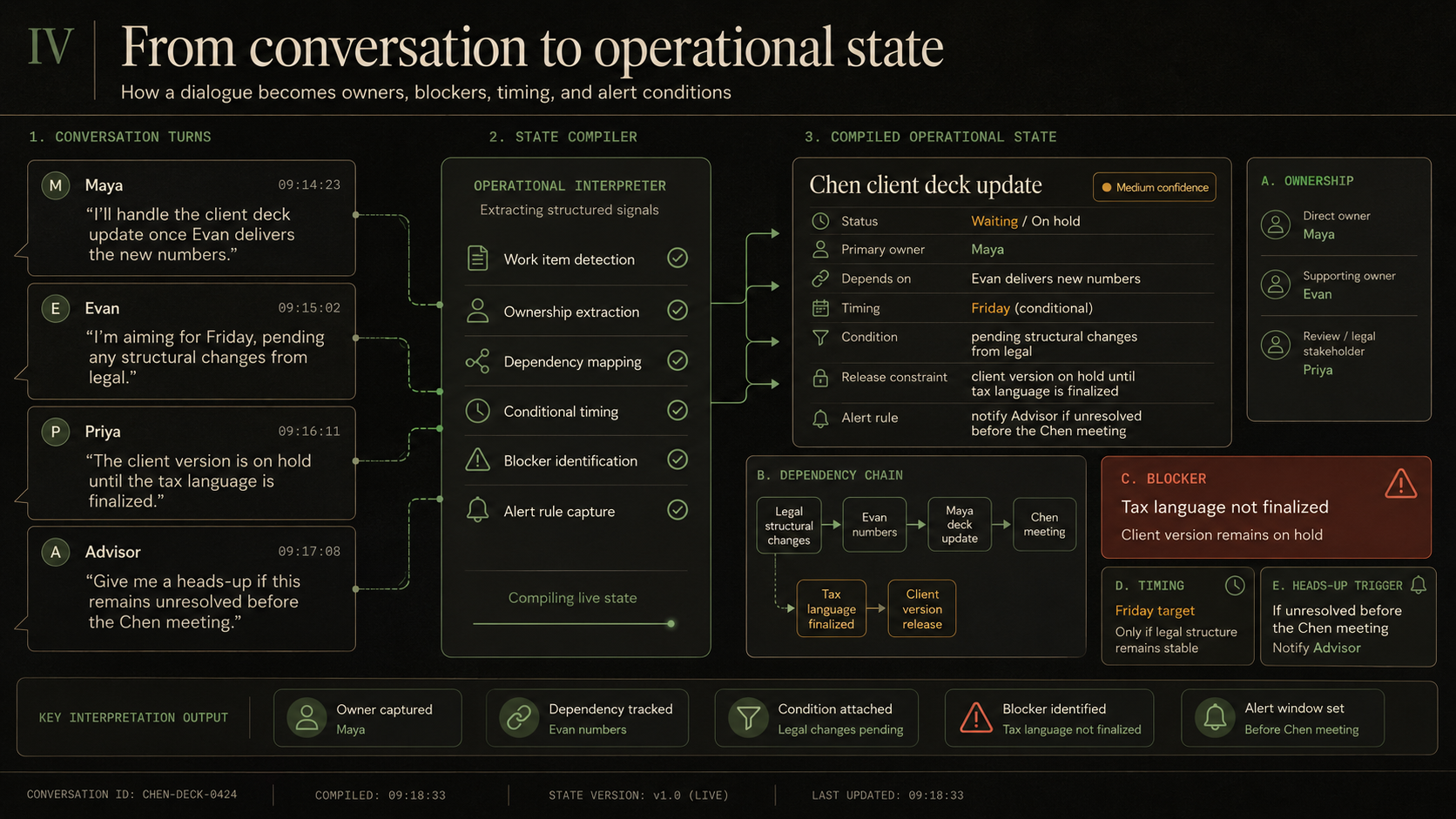
To understand why standard retrieval methods falter across extensive history, look at a typical Monday morning standup:
Maya: "I'll handle the client deck update once Evan delivers the new numbers."
Evan: "I'm aiming for Friday, pending any structural changes from legal."
Priya: "The client version is on hold until the tax language is finalized."
Advisor: "Give me a heads-up if this remains unresolved before the Chen meeting."
While basic agents might simply chunk this text or extract basic entities, a sophisticated operational partner identifies a multi-layered work state:
The deck update represents an active, unresolved thread.
- Ownership is sequential; Maya’s task is contingent on Evan’s delivery.
- Commitments are conditional, bound by external legal dependencies.
- Strict permission boundaries are established regarding the tax language.
- Temporal triggers are set for future attention (the Chen meeting).
Two months later, if the advisor asks via voice interface, "What is the status of the Chen deck?" traditional memory systems often fail in two ways:
- Latency Failure: The system sifts through hundreds of nodes to synthesize a timeline, resulting in a frustrating seven-second silence.
- Accuracy Failure: The system prioritizes a semantic match that ignores constraints, incorrectly suggesting the deck is ready.
The ideal response is crisp and informed:
"The deck is awaiting Evan's revisions. Maya will update it once they arrive, but we're still blocked by the tax language issue, so it shouldn't be sent yet."
Achieving this natural interaction requires a fundamental architectural shift.
1. Routing Prior to Retrieval
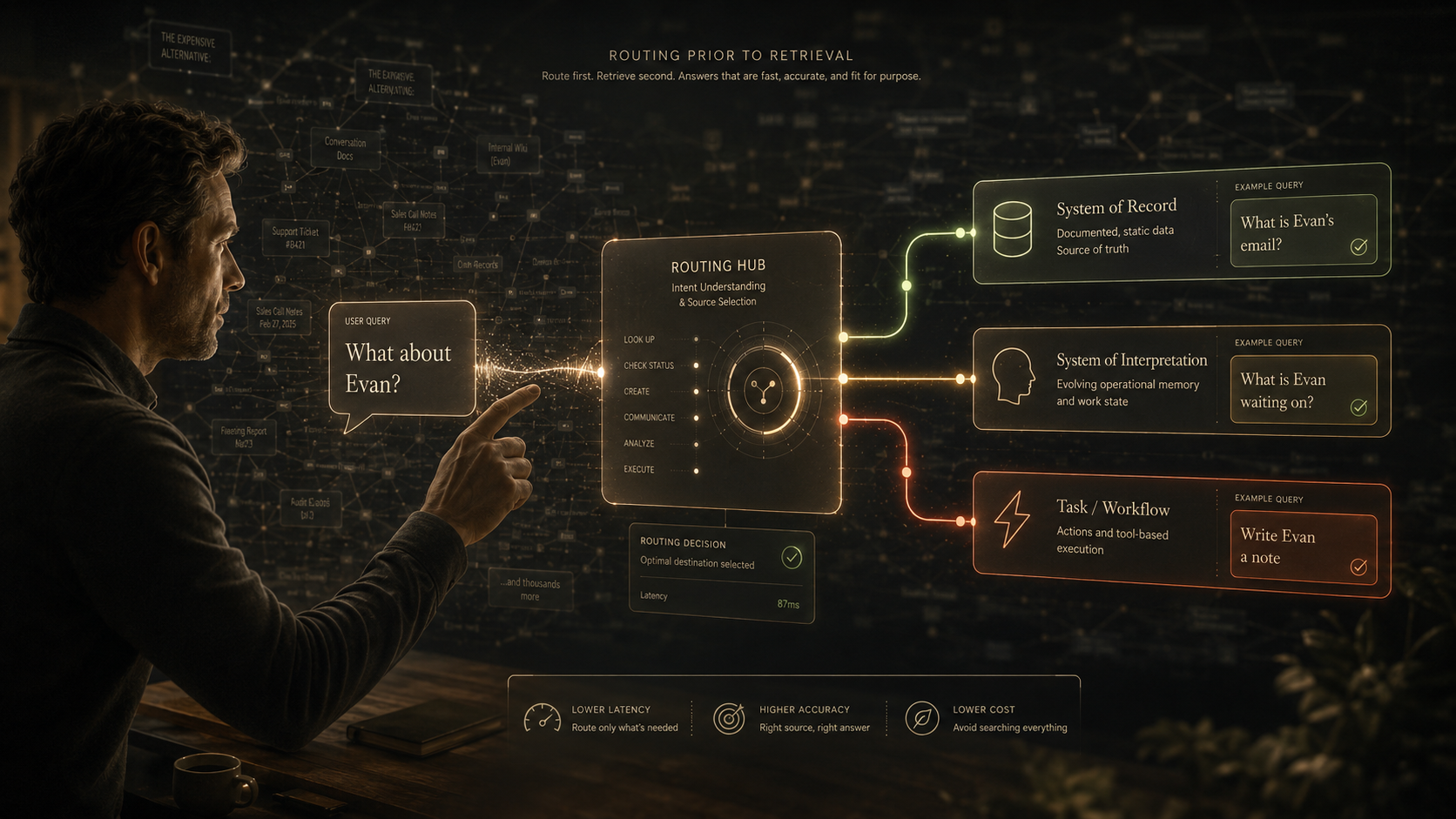
A common misconception in the generative AI space suggests that expanding context windows to millions of tokens or constructing dense semantic graphs will resolve long-term memory issues. In reality, this merely imposes an overwhelming reading task on the agent during inference.
The initial step for an agent is identifying which framework is appropriate for a given request. We address this by implementing a routing phase before retrieval, where every query is categorized into one of three specialized systems:
- System of Record: Managing documented, static data.
- System of Interpretation: Maintaining the team's evolving operational memory and work state.
- Task / Workflow: Executing actions and tool-based production.
Effective routing is vital because the same entity often exists across all three domains. For example:
"What is Evan's email?" is directed to the System of Record.
"What is Evan waiting on?" is directed to Interpretation.
"Write Evan a note" is directed to the task.
Without this preliminary routing, the system risks performing intensive semantic searches across massive archives just to retrieve basic information, such as an email address.
- Task / Workflow: Action execution and tool-driven output.
Preliminary routing is essential because entities often overlap across domains. Without it, simple inquiries risk triggering exhaustive, high-latency semantic searches. For instance:
- "What is Evan's email?" targets the System of Record.
- "What is Evan waiting on?" targets Interpretation.
- "Write Evan a note" targets the Task system.
2. Distinguishing Operational Memory from Knowledge Bases
Operational memory is an active state machine, whereas a knowledge base is a static repository of reusable facts (e.g., "What is our standard SLA?"). To function as a true participant, an agent must move beyond entity mapping to track structured work elements:
- Open work threads and their resolution requirements
- Dependencies and project blockers
- Direct and indirect ownership
- Deadlines and temporal windows
- Standing prohibitions and constraints
- Boundaries for permissions
- Levels of confidence and uncertainty
By constructing this model asynchronously, the agent converts the dialogue history into a queryable state machine rather than a simple searchable diary.
3. Specialized Indexing Strategies
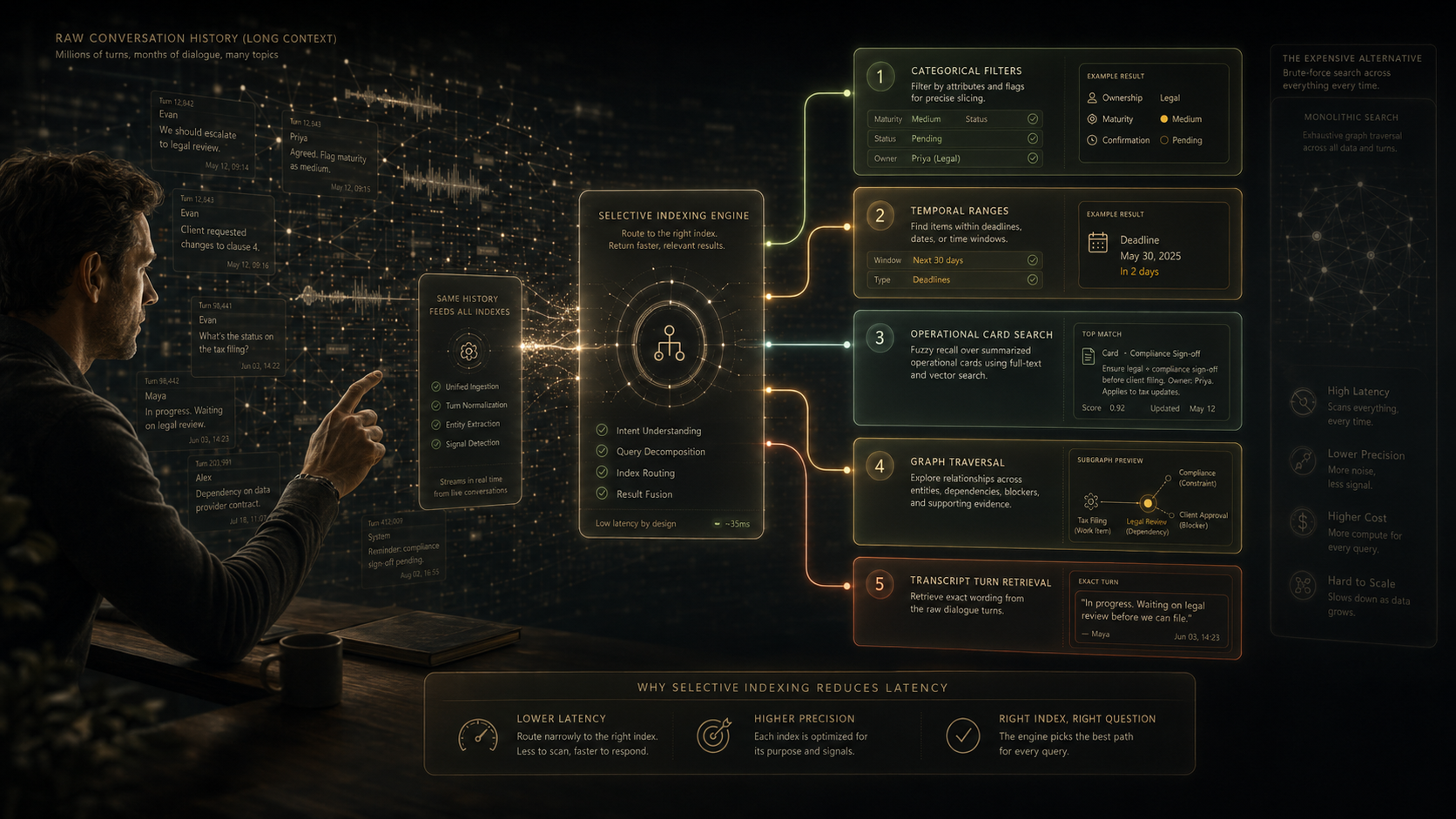
Significant latency is a common byproduct of using simple vector searches or monolithic graph traversals for extensive conversation logs. To address this, a high-performance architecture utilizes various selective indexes, each analyzing the same history for a distinct objective:
- Categorical Filters: These target explicit attributes, including maturity levels, confirmation status, and ownership details.
- Temporal Ranges: These are optimized for fetching data linked to deadlines, specific dates, or time-based boundaries.
- Operational Card Search: This utilizes full-text and vector search to enable fuzzy recall from structured, summarized "operational cards".
- Graph Traversal: This method is used to outline supporting evidence, constraints, blockers, and intricate dependencies.
- Transcript Turn Retrieval: This enables the extraction of specific wording directly from the raw dialogue logs.
Understanding the difference between turn and card searches is essential. While cards function as compact, low-latency memory objects integrated into the operational graph, turns act as noisy, high-volume evidence stored separately and retrieved only to verify exact phrasing or provenance.
4. The Dual-Layer Routing Framework
The system employs a two-tier routing architecture to manage these diverse indexes with sub-second response times.
Tier 1: Front-Door Routing
This initial layer directs incoming inquiries to the appropriate domain: Record, Interpretation, or Task.
Tier 2: Graph-Memory Routing
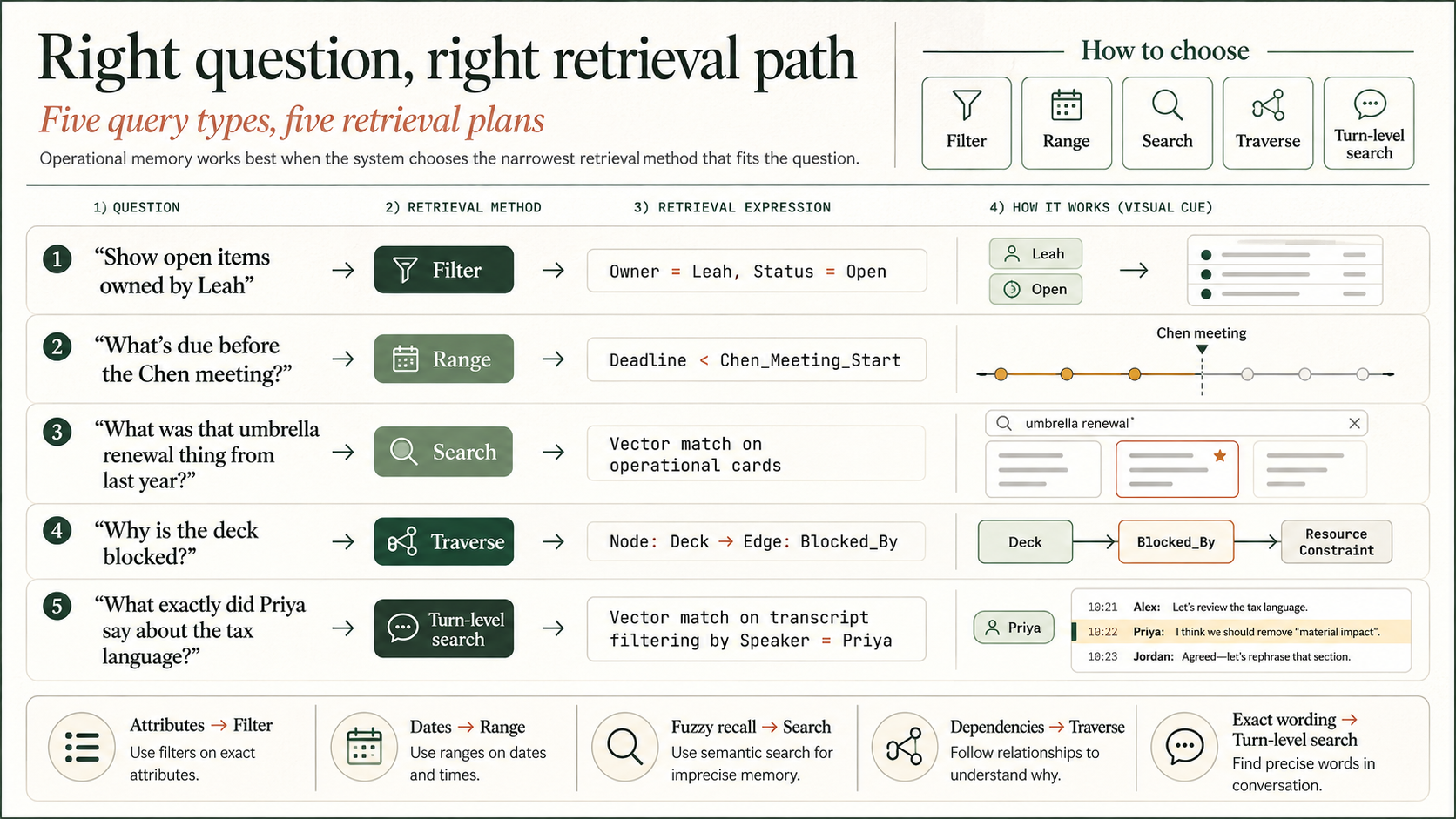
For queries routed to Interpretation, this second layer identifies the most effective retrieval mechanism: range, filter, traverse, or search.
This allows the agent to execute low-latency queries over massive time scales:
“Show open items owned by Leah” → Filter (Owner = Leah, Status = Open)
“What’s due before the Chen meeting?” → Range (Deadline < Chen_Meeting_Start)
“What was that umbrella renewal thing from last year?” → Search (Vector match on operational cards)
“Why is the deck blocked?” → Traverse (Node: Deck → Edge: Blocked_By)
“What exactly did Priya say about the tax language?” → Turn-level search (Vector match on transcript filtering by Speaker = Priya)
5. Capturing Social Nuance and Edge Cases
Authentic dialogue is rarely a tidy sequence of commands; it is often cluttered, deeply embedded in context, and shaped by social dynamics.
A simplistic approach to extracting action items from a meeting can lead to significant failures. For instance, if Maya remarks, "I can update it once Evan sends the numbers," an unsophisticated system might simply record: "Maya to update deck." Months later, the agent might mistakenly conclude that Maya neglected her responsibility.
In contrast, a sophisticated operational partner understands these social complexities. It detects hedging (e.g., should have them unless legal intervenes), identifies implied ownership, and recognizes social softening. By defining "Maya can update it" as a blocked thread substantiated by dependency evidence, rather than a simple task, the agent accurately monitors the actual progress of work over time.
6. Authority-Driven Actions
A true partner does more than just recall information; it understands its operational boundaries.
Suppose an advisor instructs the agent later that day to "Send Chen the deck." The assistant must first review the current state of the work. Upon checking the operational memory and examining dependencies, it identifies a constraint from Priya,
"Do not send the client version until the tax language is cleaned up".
Since this restriction is formally integrated as a permission boundary, the agent recognizes that it cannot proceed. It provides a secure response:
"I can prepare the email for Chen, but the deck is currently blocked by pending tax language updates. Would you like me to wait on sending?"
7. Establishing Evidence Anchors
The operational memory model serves as an interpretation, and interpretations are subject to error.
To preserve long-term trust, every interpreted memory component, including cards, edges, and states, must be linked to an evidence anchor. This anchor is a direct reference back to the specific transcript segments that informed it.
While the raw transcript remains the ultimate source of truth, the operational memory acts as the active interpretation. If an advisor questions why a project is stalled, the agent can trace back from the blocker to the evidence anchor to cite the exact dialogue, such as Priya's specific comments. This level of traceability enables humans to audit the system effectively and correct any misunderstandings of social context.
8. Latency Design for Voice
Voice interfaces have a vastly lower tolerance for delay than text chat. On a voice call, three seconds of silence feels like a system crash.
You must design the response rhythm for voice specifically:
- Immediate acknowledgment: Register the query instantly.
- Fast card/graph recall: Because operational state is pre-structured in lightweight indexes, retrieving a 9-month-old blocker takes milliseconds, not seconds.
- Concise answer: Speak the synthesized state without rambling.
- Evidence retrieval on demand: Never read the raw transcript unless the user explicitly asks for quotes.
- Bounded action: Propose actions only within known permission boundaries.
- Prioritize routing over retrieval. Avoid universal system queries when only a targeted fact or timeline is required.
- Distinguish static facts from interpreted states. Recognizing that these categories demand varying levels of confidence is vital.
- Map dependencies through graph traversal. Identify blockers as structural relationships rather than mere semantic matches.
- Formalize uncertainty. Ensure every conditional commitment includes a log of its specific conditions.
- Architect for approval boundaries. No action should be executed without first being verified against existing constraints.
- Ensure retrieval plans are testable. The router should be verifiable via unit testing without necessitating an LLM call.
The Illusion of Presence

A partner-like assistant is not created by injecting a quirky system prompt or tuning the voice model to sound empathetic. "Personality" is cheap. Trust is expensive.
An agent feels like it has been in the room for the last year because of rigorous state-tracking discipline:
It feels attentive because it tracks open threads over months without needing reminders.
It feels socially aware because it distinguishes a firm commitment from a polite suggestion.
It feels fast because it routes queries to selective indexes instead of blindly scanning an endless memory store.
It feels trustworthy because it instantly points to the exact evidence for its claims.
It feels safe because it intrinsically knows when to draft, when to ask, and when to stop.
If you want an agent that actually works alongside a team, stop trying to make it read faster. Start teaching it how to track the work.
Conclusion
The novelty of high-speed, realistic voice agents is now behind us, made possible by advancements in speech-to-speech and inference technology. However, while creating a personality is relatively simple, engineering operational trust remains a complex and costly challenge. For a voice agent to become a legitimate long-term member of a human team, we must pivot from viewing vast conversational archives as a text-retrieval hurdle to managing them as a structured problem in state tracking. Transitioning to a genuine operational ally necessitates moving beyond fleeting memory interfaces and toward a durable, structured model of the work state. Rather than focusing on how quickly an agent can read or search, the priority must be on developing an architecture that allows it to truly track work progress.