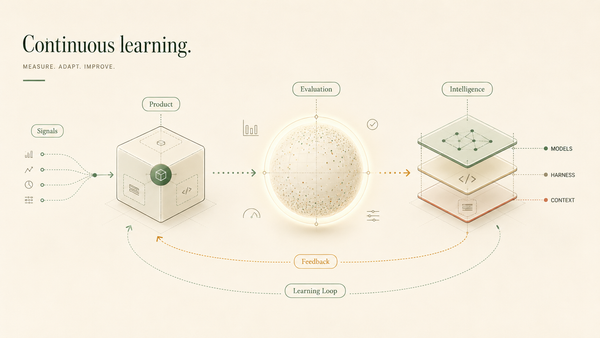
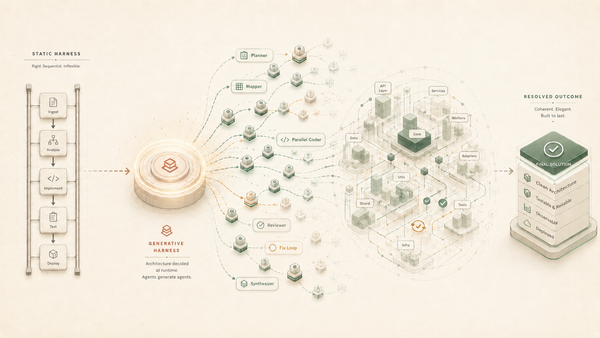
The Stateful Long-Range Dependency Problem in AI Agents


An agentic approach to building context to achieve reliable conversational intelligence.
Conversational AI agents often struggle to reason smoothly across long-horizon conversations because their contexts are disconnected. For instance, if someone says, "I'm tired," today, the agent treats it as an isolated comment without considering any broader context.
In contrast, a human manager can draw on weeks of context to make connections. They might remember a comment about quitting from a month ago and relate it to signs such as a spouse looking for work or the individual turning down new projects. Together, these clues help the manager realize that someone may be planning to leave.
Recently, there has been a lot of discussion about creating a context graph by linking isolated pieces of context from various systems of record into a unified graph. This graph can then be used to enhance calls to stateless large language models (LLMs) through graph-based retrieval. However, constructing this context as a connected graph is challenging for conversational AI agents because of the input data's unstructured nature. For instance, the input often consists of raw, unstructured call transcripts instead of well-organized information from a system of record.
I refer to this issue as the stateful long-range dependency problem. The Deep learning community has tackled a similar challenge in large language models (LLMs) by using attention mechanism within their context windows.
Similarly, AI agents require the ability to connect related information across many conversations. However, relying on runtime retrieval-augmented generation (RAG), which utilizes context stuffing and vector searches, faces a technical limitation that cannot be overcome simply by using better prompts or larger context windows. The real solution involves connecting information as it becomes available, even employing agents to help build context for future interactions, and constructing an evolving graph of data points.
Modern Agent Architectures and Their Limitations
Most conversational AI assistants, whether used for recording meetings or as enterprise tools, operate similarly. They capture conversations, segment the text or audio, and employ a language model to summarize the content and extract action items. The results are then utilized to perform various tasks autonomously, such as sending follow-up emails or completing documents.
Today’s leading AI assistants go beyond basic summaries. They allow users to search across all their meetings and provide answers that integrate information from multiple past conversations. Some even analyze themes across different clients or automatically display relevant history during meetings.
Despite these advancements, most systems still primarily focus on searching and retrieving information. They use vector searches to scan transcripts and summaries, pulling context dynamically through retrieval-augmented generation (RAG). While this approach is helpful, it does not create the lasting, long-term memory necessary for reliable intelligence, particularly in three key areas:
1. Reactive vs. Proactive Intelligence
Reactive intelligence systems respond only when a user poses a question, such as asking whether a lead appears doubtful. They are unable to identify patterns on their own. In contrast, a human manager acts on instinct, drawing from past experiences and context that they have absorbed, allowing them to make decisions automatically.
2. Chunk-Based vs. Relationship-Based Architecture
Currently, vector searches return separate pieces of text rather than presenting a cohesive story or clearly defining the relationships between people and concepts. For instance, if you search for someone's opinion on a project, you may receive several snippets, but the system does not connect the person to the project. This issue is particularly evident in conversational intelligence, where conversations are typically stored as flat, unstructured text transcripts. Users or agents must piece together the information themselves; simply retrieving disconnected chunks of conversation data only assists to a limited extent.
Important long-term signals, such as emotional trends, levels of trust, or the risk of someone leaving, are not captured in a single meeting. They emerge from patterns observed across multiple conversations. Standard Retrieval-Augmented Generation (RAG) systems cannot detect these signals in transcripts alone; instead, they need to be calculated and stored as part of the system's memory, which most tools do not currently implement.
In summary, while AI agents excel at understanding individual meetings and searching historical records, they still lack the foundation for true long-term reasoning. They cannot automatically connect small details from months ago to new developments as humans can.
The development of these capabilities can be better understood through three distinct perspectives:
1. Local Perspective: Modern systems excel at comprehending individual conversations independently.
2. On-Demand Retrieval Perspective: These systems also enable users to retrieve specific details from past meetings whenever necessary.
3. Longitudinal Perspective: What is lacking is a layer in which the agent maintains a dynamic model of individuals and their context. This would allow the agent to leverage past insights to enhance its understanding of the present.
Reliable intelligence relies on this long-term capability, which remains the primary challenge in designing modern agents.
What a human manager does differently
A manager’s understanding goes beyond just a list of notes or a summary. It involves a combination of memories, feelings, and patterns that connect people and events over time. This context influences how new information is interpreted. For instance, if a manager knows that someone is job hunting, they will take the statement "I'm tired" much more seriously than they would from someone who is unaware of that background. The same words can convey vastly different meanings depending on the manager's prior knowledge.
This illustrates a significant gap in how agents retain information: they cannot think over time as humans do and are not as effective as human brains at managing an evolving, augmenting context across conversations. This difference is crucial; it distinguishes a simple note-taker from an assistant who truly understands team dynamics. If an agent cannot accumulate knowledge from multiple interactions, it remains just a stateless tool operating behind a chat interface.
The parallel: long-range dependencies inside an LLM
Keeping track of state across conversations is similar to a classic deep learning problem within a context window: managing dependencies in a sequence of tokens. The way that problem was solved can help guide solutions for today’s agent memory issues.
In RNNs and LSTMs, information from earlier in the sequence had to pass through many steps, which often led to the loss of detail and signal fading. These models could only handle about two hundred tokens before losing track of the bigger picture and word order.
The transformer model, introduced by Google in 2017, addressed a significant challenge with self-attention. This mechanism allows each token to connect directly to every other token, making it easier to link information regardless of how far apart they are in the text.
A similar issue arises when agents handle large volumes of unstructured text, such as conversations. Unlike large language models (LLMs), which operate within a fixed context window, agents face challenges with stateful conversational data that can span weeks, months, or even years. As they handle an increasing number of tasks, they reach the limits of their memory capacity. To manage this, they tend to summarize earlier information, risking the loss of important details, much like how context can be lost in ongoing conversations. The solution is to avoid compressing information into text; instead, store it in a structured, connected format for easier retrieval later.
This represents the true limitation for today's agents. The primary challenge isn't their ability to transcribe or summarize; rather, it is the lack of a system for instantly cherry-picking and utilizing relevant context. Without such a system, agents become dependent on runtime search and compressed summaries that inevitably overlook crucial details.
Strategic Shift: Prioritizing Write-Time Intelligence
Many current efforts to enhance agent memory are misplaced. Teams often concentrate on improving Retrieval-Augmented Generation (RAG) by experimenting with new embeddings, hybrid search methods, or larger context windows. While these adjustments may enhance speed, they fail to address the core issue: the system does not effectively establish lasting connections between related data points. Relying on runtime RAG to make these connections spontaneously is a significant design oversight.
Addressing the Core: Write-Time vs. Runtime
Traditional thinking about agent memory often focuses on improving retrieval mechanisms. While smarter embeddings, hybrid searches, and multi-hop Retrieval-Augmented Generation (RAG) can enhance runtime efficiency, they don't address the central issue. The main problem is that the system fails to connect the dots within its data. Relying on RAG to handle this task is misguided.
The optimal time to link information is immediately after each interaction, rather than waiting for someone to ask a question later. Instead of merely summarizing conversations, a dedicated extraction agent should process the dialogue and construct a structured model that includes entities, relationships, and updates.
This approach is what makes the system agentic rather than merely mechanical. Basic keyword or entity extractors can identify names and topics. Still, they cannot recognize that a statement like "I'm tired" might connect back to something said weeks earlier, or that "we'll see how the next quarter goes" indicates a tentative commitment. Making these judgments requires a model that understands which signals are significant, such as concerns, commitments, life events, trust, and emotions, and retains what’s already represented in the graph. The extraction agent operates like a human manager, listening and maintaining an evolving model of each person while updating it as new information is conveyed. The graph serves as the enduring representation of this model.
This approach offers advantages that runtime RAG lacks: proactive capabilities, relationship management, and state awareness, allowing the agent to perform autonomous tasks with rich context. It represents individuals and projects as nodes linked by connections, making it easy to track changes over time. Trust and departure risk are integral parts of the model, continuously updated as new information is received, rather than reconstructed from scratch each time.
It transforms long-term memory into a straightforward, reliable process rather than treating it as a runtime search problem.
Where the design effort actually lives
Choosing the right search strategy is not the main challenge. Graphs, vectors, or hybrids can all help fetch relevant data points. The real difficulty lies in identifying the types of information that matter for cross-conversation intelligence in your domain and determining what the extraction agent should focus on.
When developers rely on runtime Retrieval-Augmented Generation (RAG), they make a risky choice. They forgo extracting important signals at write-time and hope that embeddings and searches will later uncover what matters. This approach assumes it is safer to avoid making decisions about what is important. However, in fields where subtle signals, such as trust or emerging concerns, accumulate over time, this method fails. If these insights are not captured and labeled during extraction, they are lost from the data.
Projects like the Hermes Agent from Nous Research demonstrate that a different approach can be effective. Hermes utilizes Honcho as its memory layer, enabling it to learn from ongoing interactions rather than just searching through past transcripts. By combining Honcho's write-time reasoning with a runtime context layer, Hermes provides a practical example of this agent-based architecture.
Architectures like Honcho and temporal knowledge graphs (such as Graphiti or Zep) organize data in distinct ways; some focus on entities, while others emphasize graph paths. However, they share the same core principle: relying solely on runtime RAG is insufficient. Both suggest that important data connections should be established at write time by a reasoning agent and stored persistently. The choice between these architectures depends on whether you want to concentrate on individual entities or track relationships over time. To move from static tools to agents with real long-term intelligence, we need to shift the work of connecting information from runtime to write-time. In this setup, the graph becomes the living record of ongoing intelligence.
Conclusion
To effectively develop a context layer, it is essential to connect relevant information into a cohesive graph using an agentic approach. This transition shifts the process of building context from a one-time task to an ongoing, proactive effort that operates in the background. As a result, this creates a context layer that downstream agents can leverage to perform tasks with high accuracy, rather than having to piece together and make sense of disconnected information during runtime.