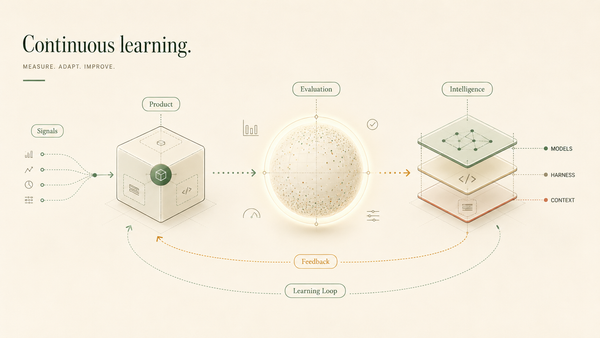
Treating AI Operational Memory as Git like Version-Controlled State
For reliable autonomy, AI memory must adopt the rigor of version control: transparency, auditability, and the ability to roll back.

AI memory engineering has moved beyond basic vector stores and standard RAG. We are now seeing the rise of sophisticated architectures like tiered archival systems, self-evolving core prompts, and dynamic GraphRAG.
However, as agents transition into long-running collaborators, the primary challenge has shifted from context retrieval to state management.
Memory for an agent acting on a user's behalf cannot be a passive repository or a mutable graph prone to overwriting. Instead, it must be treated as an interpreted operational state. Because these states result from probabilistic interpretations of complex human interactions, every update must be tracked with the same rigor as a version control system.
The Intricacy of Human Conversation

Visualize an AI agent attempting to follow a project meeting characterized by this rapid exchange:
- "We require three distinct workstreams: a launch plan, legal review, and the customer email."
- "The email needs legal clearance first."
- "Alex, are you able to send it once it is approved?"
- "Hold on, Morgan should take charge of the email; Alex needs to prioritize the analysis."
- "Reschedule that task for next Wednesday."
- "Apply the same for Arjun, but with less intensity."
- "Can you send that out as well?"
Humans navigate these shifting ownerships, dependencies, and vague pronouns with ease. However, for AI, this is a treacherous landscape. Most current memory frameworks falter when tracking these quick state transitions without sacrificing essential context or introducing inaccuracies.
An AI agent must simultaneously manage permission boundaries, prevent data duplication, and resolve dangling references. This complexity is precisely where contemporary state-of-the-art memory systems often fail.
The Shortcomings of CRUD in Operational Memory
Solving current architectural failures requires a clear distinction between static semantic memory (facts and policies) and operational memory. This operational layer is an agent's active, interpreted map of commitments, blockers, and deadlines.
Rather than simply recording statements, operational memory captures the agent's internal understanding of their implications.
While knowledge graphs and core memory structures have evolved, memory management remains tethered to the CRUD model. This dependence on destructive mutation is a major vulnerability; frequent updates often overwrite the underlying reasoning, eroding provenance and fueling compounding hallucinations.
The Illusion of Advanced Memory (And Why CRUD Fails)
To understand the architectural failure, we must separate static semantic memory (facts, docs, policies) from operational memory, the agent’s current, interpreted graph of active commitments, owners, deadlines, dependencies, blockers, permissions, and unresolved ambiguities.
Operational memory is not “what was said.” It is “what the agent currently believes follows from what was said.”
Even with advanced memory structures like dynamic knowledge graphs or agent-maintained JSON core memory, the industry still treats memory as a CRUD (Create, Read, Update, Delete) database. This reliance on destructive mutation creates massive operational vulnerabilities:
- Lost Provenance: When an agent decides a user’s goal has changed, it updates a node in the graph or rewrites a block in its working memory. The overwrite destroys the context of why the timeline was pushed to Wednesday or what legal is actually reviewing.
- The Poisoned Graph Problem: GraphRAG is incredibly powerful for reasoning, but uniquely painful to debug. If an agent misinterprets a transcript and injects a hallucinated dependency into the graph, that bad node will be retrieved in future context windows, creating a compounding feedback loop of hallucinations. Without diffs and rollbacks, untangling that poisoned node is a nightmare.
- Multi-Agent Race Conditions: As you move to multi-agent architectures, different sub-agents operate on the same memory asynchronously. Agent A decides "Legal Review" is blocked, while Agent B, processing a parallel tool call, marks it Complete. Without a system to merge and reconcile candidate commits, the last LLM call to write to the graph blindly wins.
Defining Agent Belief Transitions
A belief transition occurs whenever an agent updates its internal understanding of truth or operational priorities. This includes actions such as:
- Initiating new tasks or communication threads.
- Modifying deadlines or task ownership.
- Identifying new dependencies or operational blockers.
- Clarifying and resolving linguistic ambiguities.
- Consolidating redundant or overlapping threads.
- Adjusting security and permission boundaries.
- Canceling or superseding previous objectives.
Core Pillars of Operational Memory
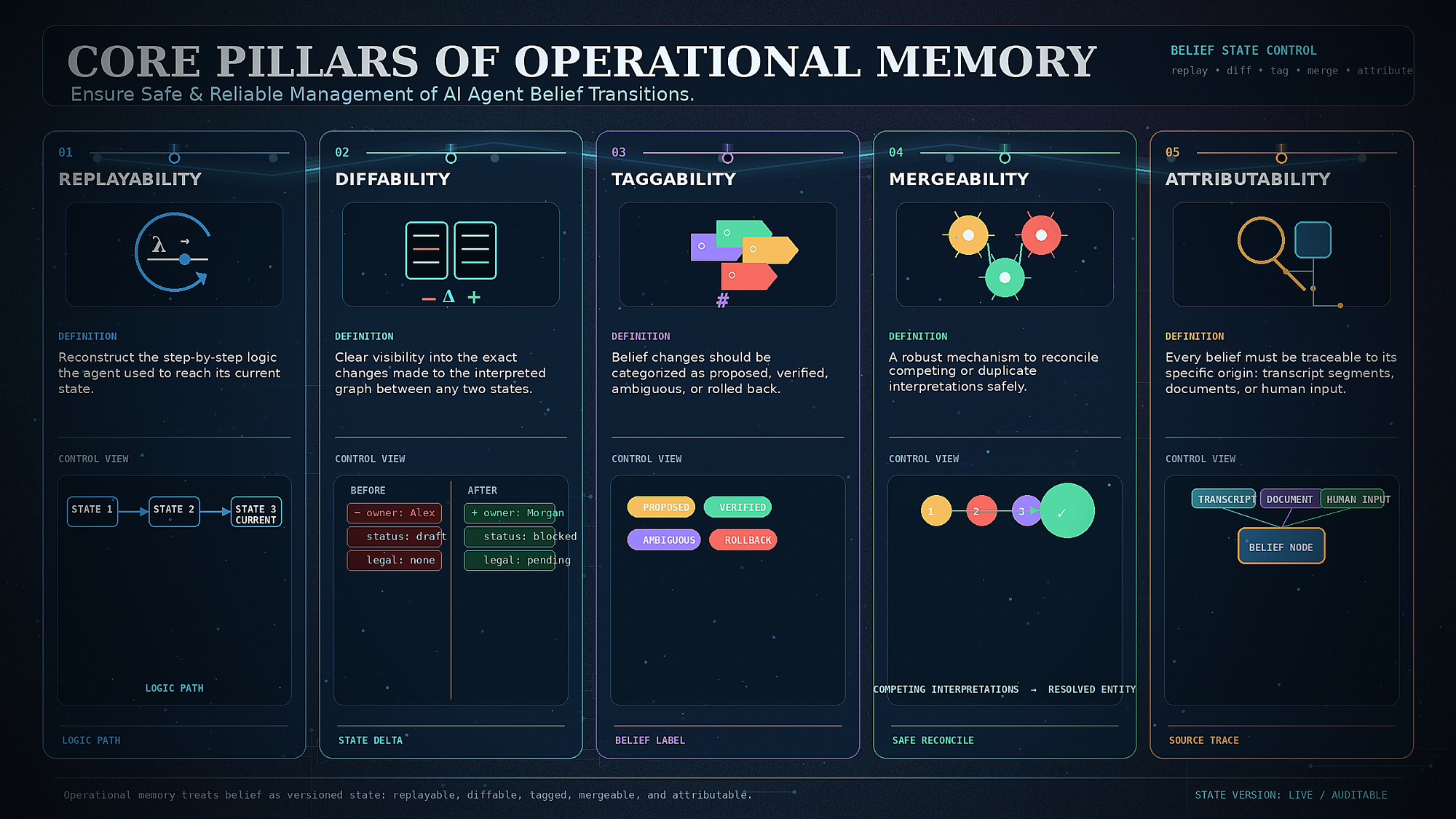
To ensure safe and reliable management of these transitions, an agent's operational memory must be built upon five essential pillars:
- Replayability: The ability to reconstruct the step-by-step logic the agent used to reach its current state.
- Diffability: Clear visibility into the exact changes made to the interpreted graph between any two states.
- Taggability: Belief changes should be categorized (e.g., proposed, verified, ambiguous, or rolled back).
- Mergeability: A robust mechanism to reconcile competing or duplicate interpretations safely.
- Attributability: Every belief must be traceable to its specific origin, whether it be transcript segments, documents, or human input.
Applying Git Principles to AI Memory
Effective software collaboration relies on more than just editing files; it involves proposing edits, reviewing changes, branching to address uncertainty, and reverting errors. To achieve true reliability, AI operational memory must adopt this same systematic rigor. By treating the state graph as a view of an immutable event log, we can map core Git workflows directly to agent state management:
A critical distinction: Versioned memory is not a shortcut to general intelligence or superior zero-shot reasoning. Rather, its value lies in providing auditability, trust, and secure autonomy. By implementing governance within multi-agent architectures, we ensure that systems fail gracefully rather than experience catastrophic breakdowns.
Traceability via Immutable Logs and Observable Rationale
To implement this framework, systems must utilize an immutable trace log. Rather than burying logic in unparsed, internal chain-of-thought strings, the system should output an observable rationale. This provides a transparent, auditable breakdown of the decision-making process, including the evidence utilized, discarded alternatives, confidence levels, and verification outcomes.
The log must record every step of the agent's journey:
- Initial input perceived by the agent.
- Specific context pulled from the graph.
- Evaluated candidates and the reasons for their rejection.
- The final proposal and its supporting evidence.
- The identity of the verifier or human who provided approval.
- The specific graph delta and state comparison (before vs. after).
Prioritizing Ambiguity as a First-Class Citizen
Consider the command:
"Repeat that for Arjun, but lighter. Send that over as well."
Instead of forcing a probabilistic guess to satisfy a rigid schema, the agent should categorize this uncertainty as a first-class object. By creating provisional fragments or branches, the agent can actively monitor the conversation for missing context or request clarification. This ensures that ambiguity is managed as a deliberate operational state rather than being lost to over-summarization.
Conclusion
Reliable AI partners must manage commitments with transparency and precision. Their utility depends on tracking the historical evolution of these commitments, not just current data points. A version-controlled framework naturally answers critical questions:
- "What was the logic behind this assignment?"
- "When and why was the deadline changed?"
- "Is this a finalized decision or a proposal?"
- "Can we revert the most recent interpretation?".