AI Memory: Rethink it as an Index, Not a Database
Why conversational systems require pointers over payloads


Proposing to a database engineer that they index every single column in a massive table will likely earn you a look of sheer disbelief, as if you had suggested laminating the entire ocean. The reality is that indexes incur high costs: each addition slows write operations, consumes excessive storage, and complicates the query planner's decision-making. The established, effective discipline is straightforward: index only the columns required for filtering queries and rely on full scans for everything else.
Currently, agent memory systems struggle with this same lack of discipline, falling into two extreme camps:
- The Over-Indexers: These architectures attempt to pre-compute understanding during ingestion, much like an over-ambitious DBA. They resolve every entity, type every relation, and validate every fact into a sprawling knowledge graph or bloat vector databases on the off-chance information might be queried later.
- The Non-Indexers: In direct opposition, this camp builds systems with no indexes at all. They simply chunk and embed raw transcripts, essentially performing a fuzzy full-table scan for every single question posed to the agent.
The recent paper Chronos: Temporal-Aware Conversational Agents with Structured Event Retrieval for Long-Term Memory (arXiv:2603.16862) provides a glimpse into this mindset. By treating agent memory with the discipline of a database engineer, it focuses on building a single index for the one column that long-term memory queries depend on most, yet language models struggle with most: time.
While keeping other data as raw, scannable dialogue, this architectural shift yields impressive results, achieving 92.6% on LongMemEval with GPT-4o and 95.6% with Claude Opus 4.6. This performance outperforms both pure-retrieval minimalists and graph maximalists, illustrating why agentic AI must transition toward viewing memory as an index rather than a monolithic database.
The Price of Extensive Extraction
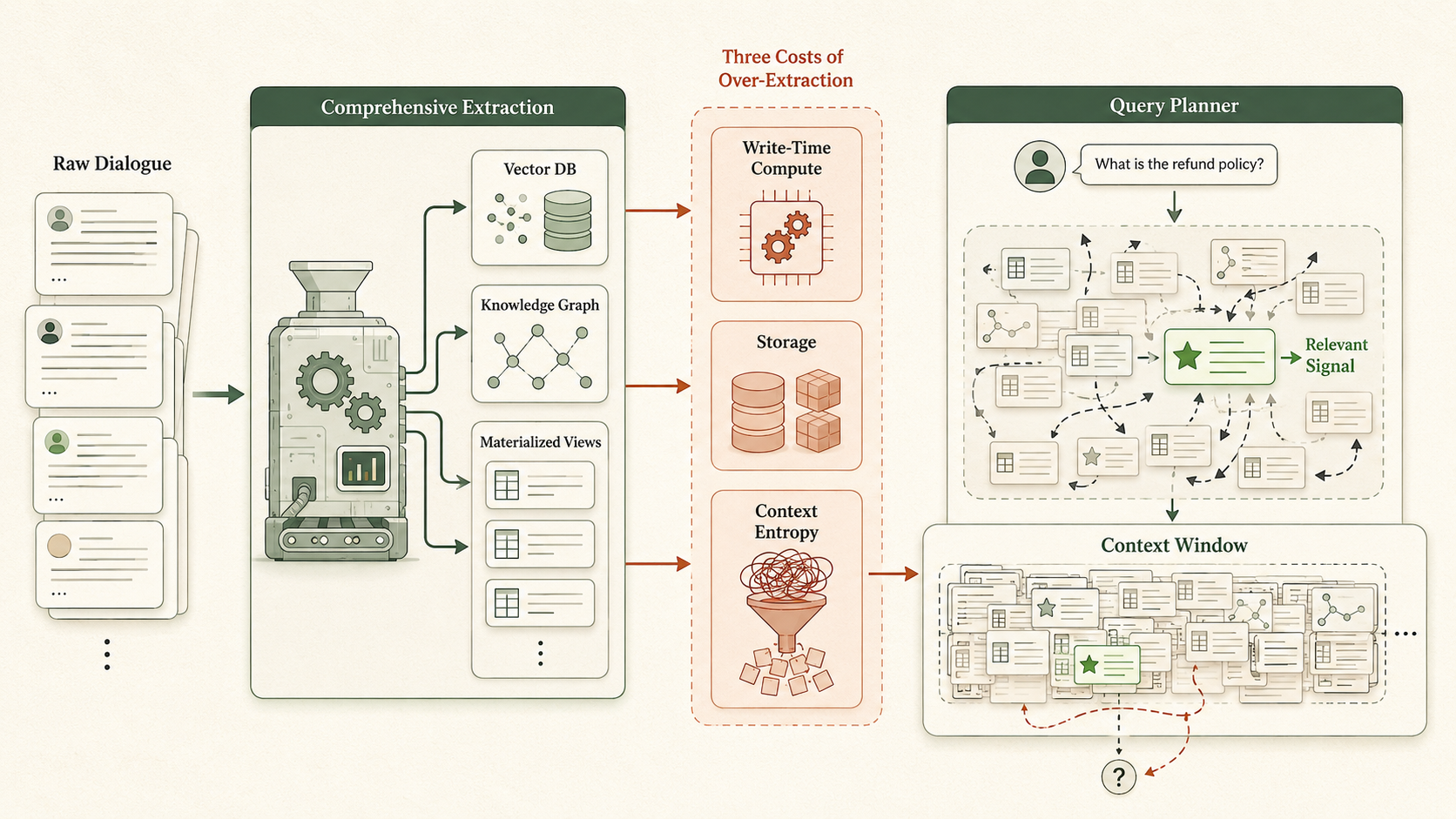
In database terminology, comprehensive extraction, such as info stored in a vector database or a knowledge graph during ingestion, functions as a set of materialized views generated prior to any query. While effective when they align with the workload, mismatched materialized views incur three distinct costs: write-time computation, storage, and a subtle read-time penalty.
This read-time burden is known as context entropy. Irrelevant pre-computed knowledge is not benign; it competes for retrieval priority, congests the context window, and presents the model with a deceptively structured but irrelevant framework that misguides the query planner.
Performance metrics highlight this trade-off: advanced temporal knowledge graphs like Zep achieve 71.2% on LongMemEval, whereas a "no index" approach of providing the full conversation history scores only 60.2%. Both excessive indexing and total lack of indexing prove suboptimal.
Indexing the Vital Column
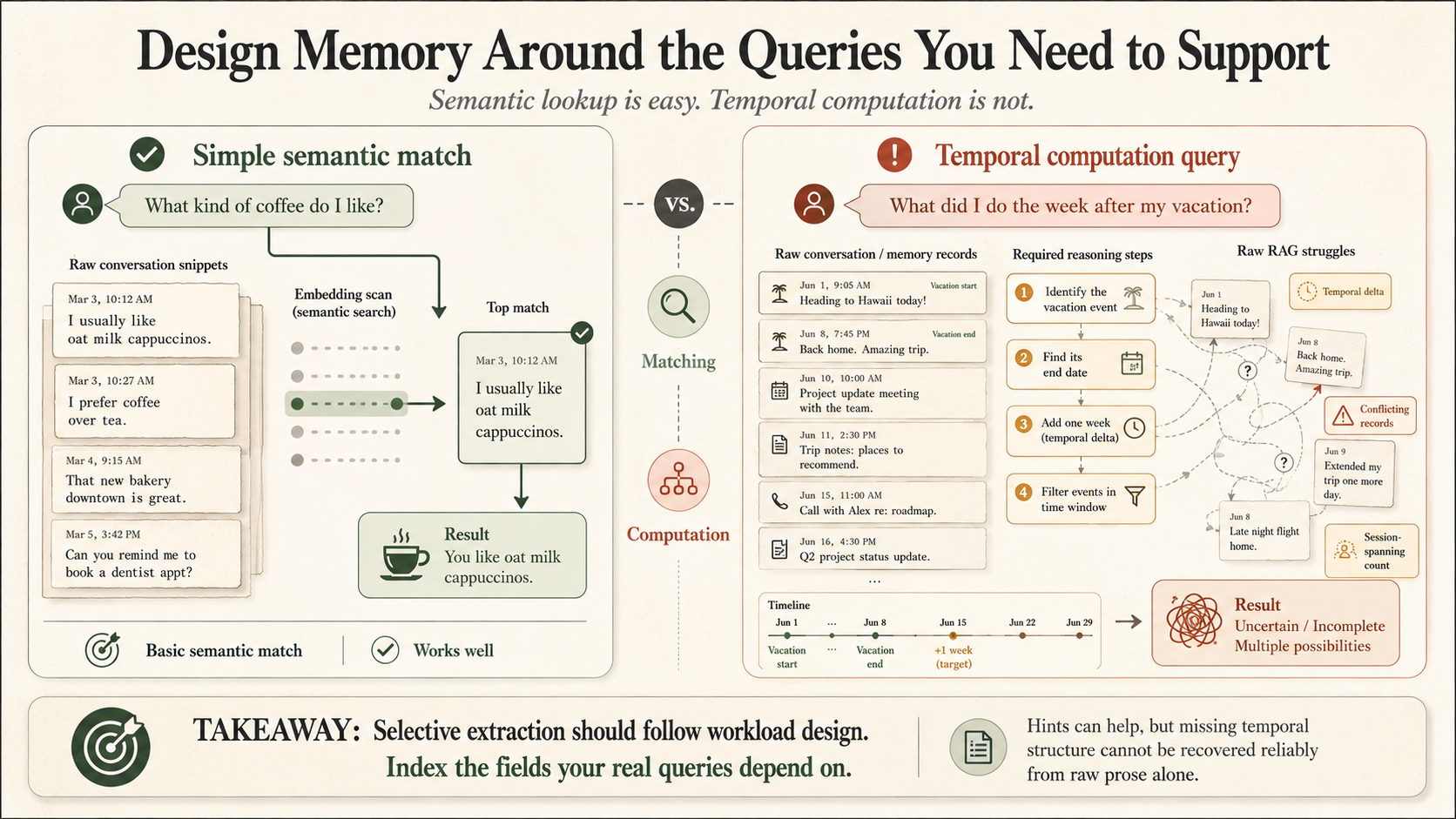
The breakdown of the full-scan methodology is highly transparent. By deferring all interpretation to read-time, raw RAG succeeds only with basic semantic matches. A query like "what kind of coffee do I like?" functions as a simple WHERE clause that embeddings can reasonably handle.
However, a prompt such as "What did I do the week after my vacation?" shifts from matching to computation. It requires identifying the vacation, pinpointing its conclusion, adding a week, and filtering events accordingly. Forcing a language model to perform this calendar arithmetic on raw prose exposed its inherent weaknesses in handling temporal deltas, session-spanning counts, and resolving N conflicting records.
The key is to be aware of the nature of the lookups/queries you want to support and to design your selective extraction around them.
Treating the workload like a slow-query log reveals that time-based queries are the primary source of timeouts and hallucinations. Since time is the filtering column for these failures, that is the only column you should index.
To solve this, Chronos generates an "event calendar" by extracting subject-verb-object tuples from dialogue. Each tuple is mapped to a resolved ISO 8601 datetime range rather than a vague estimate. Vague terms like "recently" are transformed into specific windows relative to the conversation, while explicit dates are captured precisely. This evolution replaces fuzzy string interpretation with a definitive range-intersection filter.
The Agentic Memory Manifest: Lessons from Iceberg
Data lake engineers avoid compute-intensive scans of raw object storage by using metadata management systems such as Apache Iceberg. These manifests identify the specific location and timing of transactional changes without processing petabytes of data. Chronos applies this logic to AI through a time-indexed event calendar that serves as a metadata manifest, guiding agents to relevant information while avoiding the burden of loading entire conversation histories into working memory.
While the index remains compact, Chronos maintains the integrity of the source data by storing raw dialogue in a parallel "turn calendar.". The base table is preserved in its entirety. This architecture ensures that while indexes can be regenerated, the original conversational context, which would be lost if summarized into a graph, remains accessible.
Adapting Multi-Agent Swarms through Flexibility
The transition from a database-centric to an index-centric model is vital when scaling from individual chatbots to intricate multi-agent ecosystems, including those employing Graph memory architecture. Forcing every specialized agent to ingest and analyze a user's entire raw history can lead to system paralysis when token overhead becomes unmanageable.
Instead, by using a chronologically precise, structured index of events, agents can achieve full temporal clarity with minimal computational overhead. Enterprise teams working on-premises frequently rely on rigid vector databases for knowledge management, yet an architecture grounded in selective, lightweight indexing offers the flexibility needed to pivot among various local models and limited context windows. This shift demonstrates that architectural flexibility ultimately outweighs the benefits of rigid control.
Guidelines for index design

Subject any fact destined for agent memory to the same rigorous evaluation as a potential database index before it enters the ingestion pipeline:
- Identify a specific, practical query pattern that the data should facilitate.
- Design one or multiple selective extractions purely to serve those queries and index them.
- Build an agentic search that routes/maps the query to a specific type of index derived from selective extraction and constructs the answer to the query.
Conclusion
The progression of AI memory is fundamentally about establishing more precise pathways to existing knowledge rather than expanding information silos. By adopting disciplined database engineering methodologies, systems can bypass the inefficiencies of early agentic architectures by prioritizing critical temporal indexing and preserving raw conversational data.
The path toward sophisticated long-term memory is defined by strategic restraint: focusing on essential retrieval markers, keeping raw context intact for future discovery, and maintaining the agility of the underlying agents. Memory serves as a navigation instrument rather than a mere accumulation center; its primary function is, and should remain, that of an index.