Reusable Knowledge vs. Operational Memory
The missing distinction in building AI agents that can actually follow through


We have finally stopped treating the vector database as a magic box.
The industry has matured. Teams building production-grade AI agents are no longer simply chunking PDFs and hoping semantic similarity will solve memory. We are designing richer context systems: agent-curated memory, hierarchical context trees, semantic graphs, provenance trails, and adaptive lifecycles that decide what should be retained, strengthened, or allowed to decay.
That progress matters. Better memory makes agents less stateless. It helps them understand users, projects, codebases, preferences, policies, and recurring patterns.
But as agents move from answering questions to participating in long-running work, a new design problem appears.
Remembering more context does not automatically tell an agent what is currently open, what is blocked, what should happen next, or when a workflow should stop. Those questions become especially important when the agent is expected to operate across meetings, messages, documents, approvals, and asynchronous follow-ups.
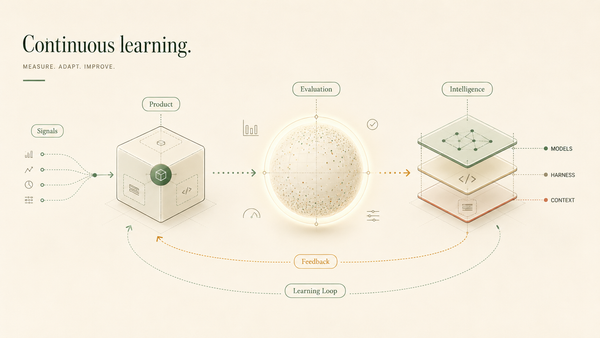
The subtle architectural blind spot is that we often treat too much of memory as reusable knowledge.
Reusable knowledge is the agent's evolving encyclopedia. It tells the agent what to know next time.
Execution needs something different. Execution needs Operational memory: A durable state model of what is still open, what must happen next, what must happen first, who owns the next move, when attention should return, and what would count as done.
A proactive agent needs more than just a better encyclopedia.
It needs a state machine.
This post is the sixth installment in my exploration of proactive agent design. This piece focuses on the memory layer underneath all of them.
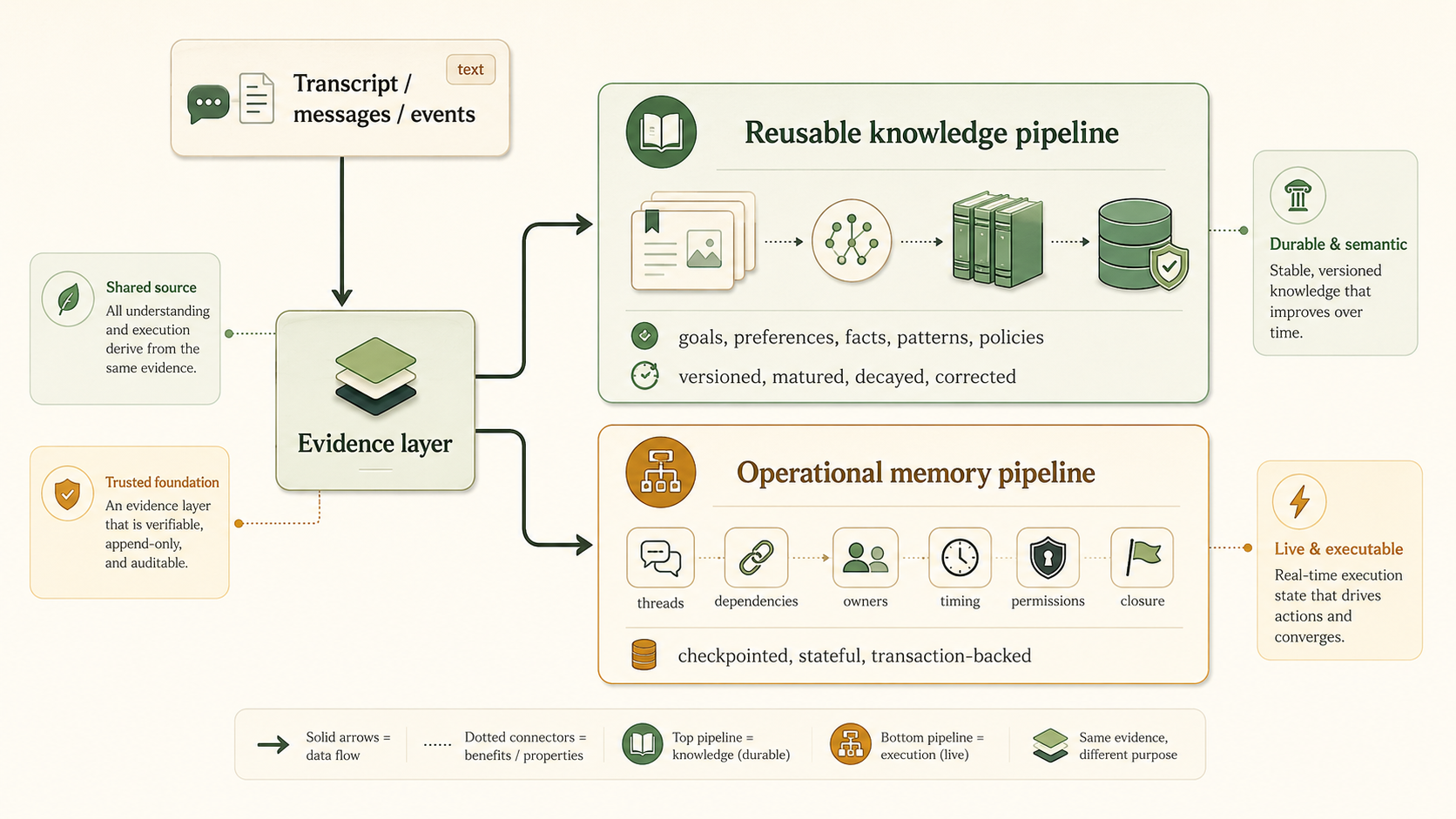
The solution is not to discard reusable knowledge systems. It is to recognize that a complex agentic application requires multiple memory architectures running on the same evidence: one for durable knowledge and one for executable state.
The Illusion Of Execution
Modern task agents can look very capable. Coding agents, workflow agents, and tool-using assistants can perform long sequences of actions: edit files, run tests, query APIs, create tickets, summarize results, and produce final reports.
This does not mean their work is simple. If a user says:
Build a food ordering app for Mexican restaurants.
The agent still has to make many decisions. It must choose screens, data models, user flows, styling, validation rules, error states, and implementation details. There is still ambiguity, judgment, and planning.
But the task has been explicitly delegated. The user has already said that an app should be built. The agent's job is to turn that delegated objective into a design and implementation plan.
That is different from being dropped into an ambient stream of work where no one has explicitly specified the task.
A developer might say:
Refactor this database schema and run the unit tests.
Or they might say:
Build a food ordering app for Mexican food.
Both prompts may require substantial reasoning. But in both cases, the agent starts with an explicit assignment.
Proactive agents do not get that luxury.
They sit in meetings, read Slack threads, monitor client emails, and observe work as it emerges. In those environments, tasks are rarely handed down as clean instructions. The agent has to infer that work exists at all.
People speak in fragments, dependencies, pronouns, deferrals, conditions, and assumptions.
The hard part is not simply executing a task.
The hard part is conversational compiling: turning messy human dialogue into an execution graph.
The agent has to infer what needs to be done without being explicitly told, then reconstruct the order, dependencies, sequence, temporal triggers, ownership, and closure conditions on its own.
A retrieval-heavy memory layer cannot do that on its own.
Reusable Knowledge: The Self-Updating Wiki
The first memory contract is reusable knowledge.
Reusable knowledge answers:
What should the agent know next time?
It is durable, cumulative, and evolving. It captures stable context about users, teams, projects, clients, preferences, environments, and recurring patterns.
The user prefers concise updates.
This codebase uses React Query for server state.
The client dislikes surprise tax bills.
The advisor prefers client-facing emails as drafts.
The firm requires approval before external messages are sent.
The client's CPA is Ravi.
This kind of memory is essential. Without it, agents feel shallow and repetitive.
Recent memory architectures have significantly improved this layer. ByteRover, for example, is useful because it moves beyond raw vector recall. It treats memory as an agent-curated, hierarchical context rather than a passive pile of embedded chunks. Its context tree structure, importance scoring, maturity transitions, and decay policies are all aimed at maintaining reusable knowledge more cleanly.
That is the right direction for a durable context.
But a self-updating wiki, no matter how well curated, cannot by itself manage execution.
Where Reusable Knowledge Stops
Reusable knowledge is not flawed. It is doing the job it was designed to do.
A self-updating knowledge base helps the agent maintain orientation. It gives the agent durable context about the user, the project, the client, the environment, and the patterns that matter over time. Without this layer, operational memory would be brittle because every task would be interpreted without background understanding.
For example, reusable knowledge might tell the agent:
The client dislikes surprise tax bills.
The advisor prefers client-facing emails as drafts.
The firm requires approval before external communication.
This context is essential. It shapes how the agent interprets and executes future work.
But reusable knowledge alone is not sufficient because execution asks different questions.
A knowledge base can tell the agent that the advisor usually prepares filing packets. It can tell the agent that the client is working on the FY25 filing. It can remember that a bank statement was discussed.
Operational execution requires a more specific state:
That is not merely a durable context. It is an active coordination state.
The difference is one of purpose:
Reusable knowledge helps the agent understand the situation.
Operational memory helps the agent manage what should happen next.
A reusable knowledge layer can support execution by providing background context, preferences, policies, and historical patterns. But the execution layer still needs its own structured state: dependencies, ownership, timing, permissions, readiness, and closure.
So the point is not that the wiki fails. The point is that a wiki is not a scheduler, a dependency tracker, or a state machine.
A proactive agent needs both:
Durable knowledge for orientation
Operational memory for coordination
Operational Memory: The Executable State Model
Operational memory answers a different question:
It is the agent's interpretation of natural language into an executable state.
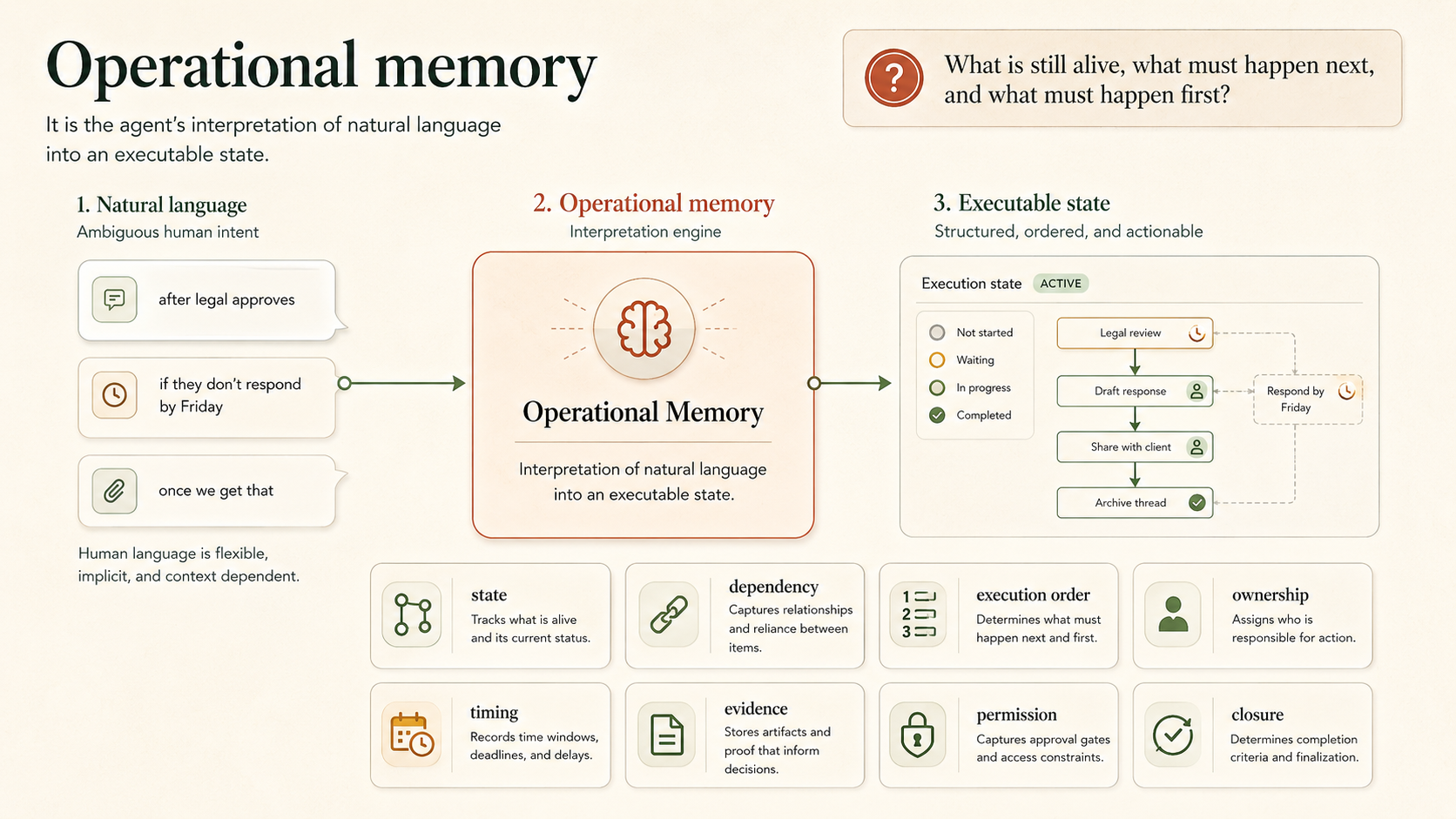
It tracks:
In a proactive agent, global memory can be thought of as two related but distinct parts:
semantic context + execution state
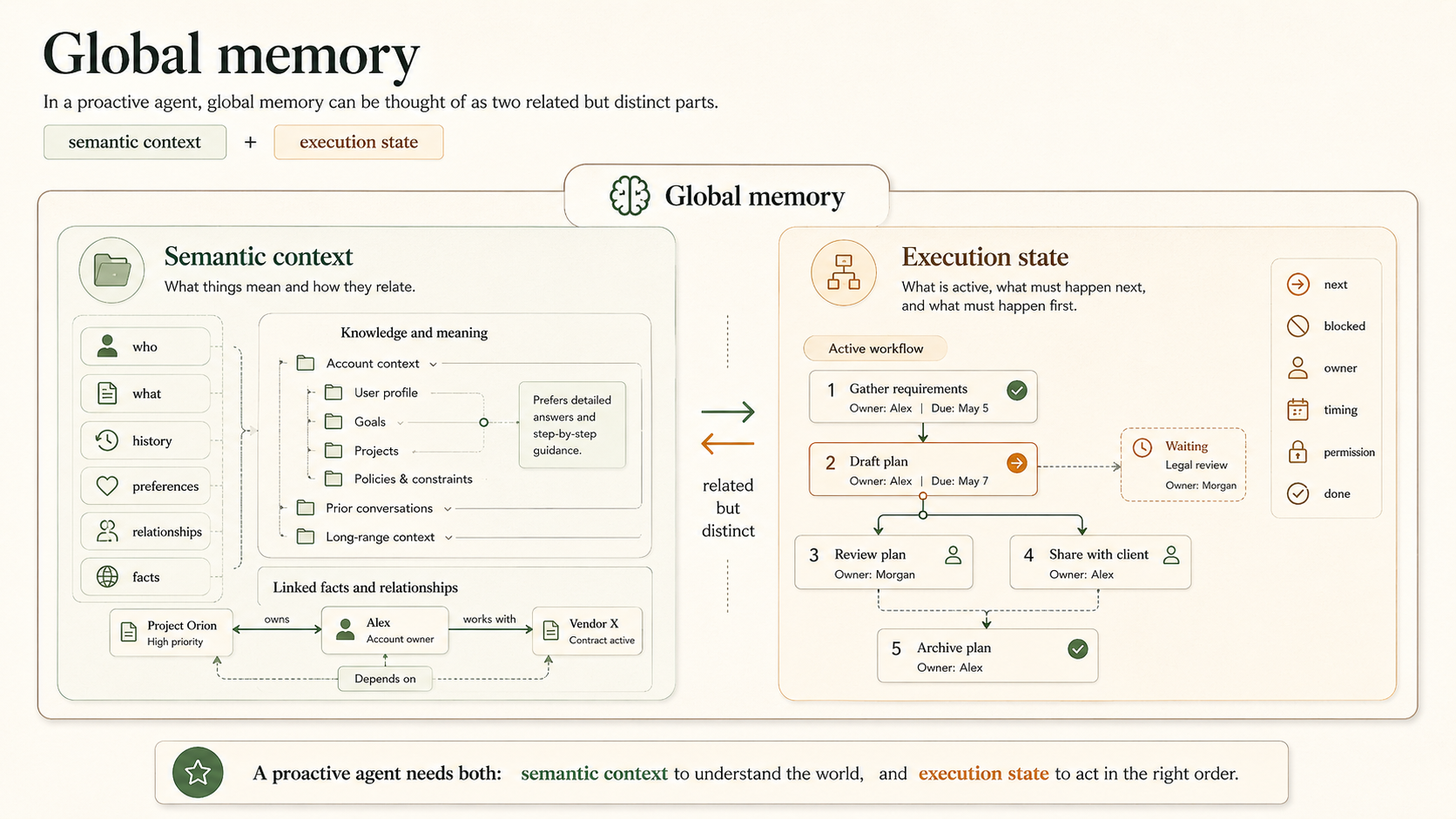
Semantic context is reusable knowledge: what the agent knows about the user, project, client, or environment.
Execution state is operational memory: what is currently open, blocked, pending, ready, or resolved.
For a reactive chatbot, execution state is often trivial. The user asks a question, the model answers, and the loop ends.
For a proactive agent, the execution state must survive time. It must persist while the agent sleeps, wake when new evidence arrives, and resume without rereading the entire history.
That is why operational memory should behave more like a transaction-backed state machine than a document store.
Natural Language Is The Hard Part
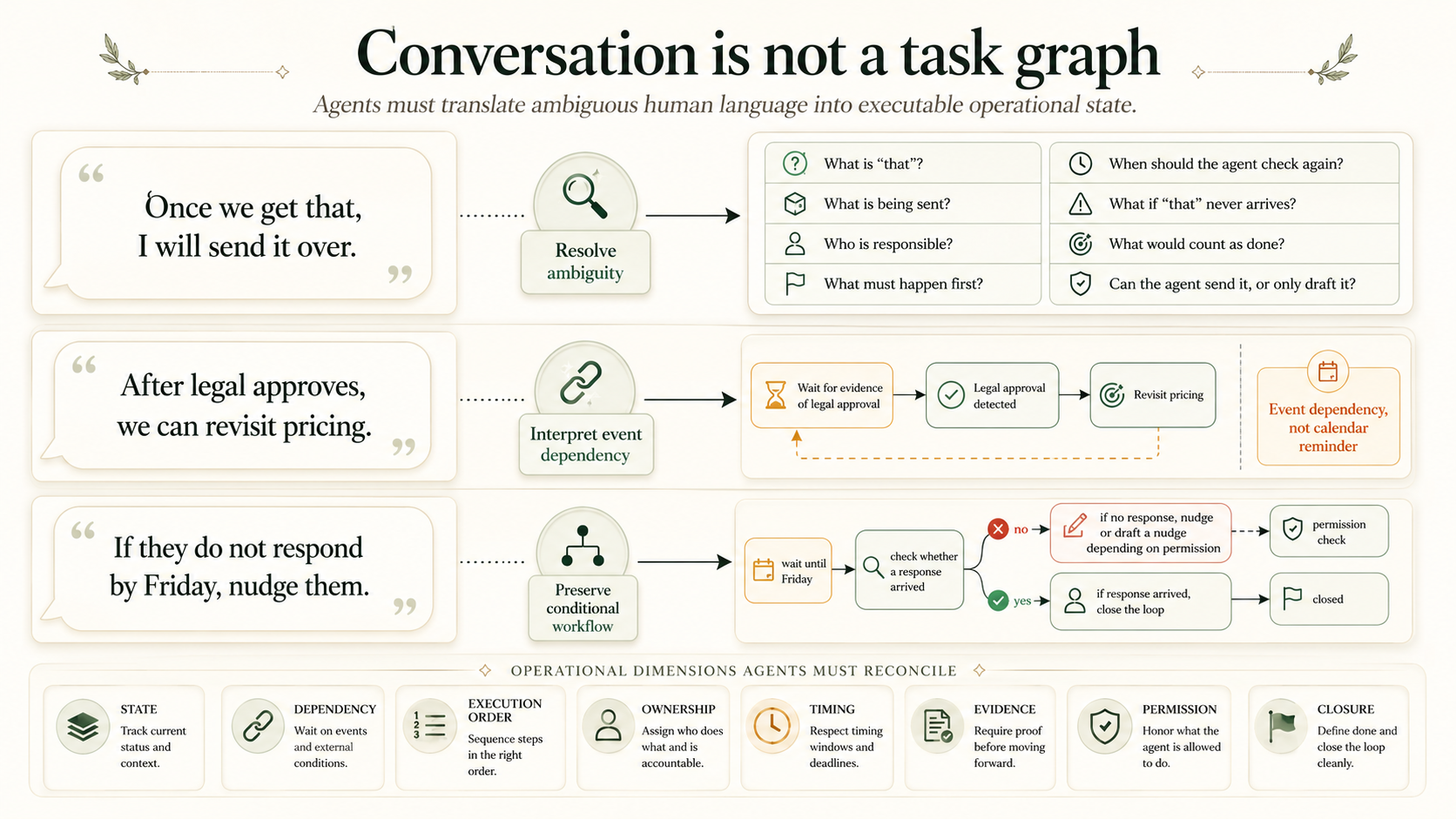
Operational memory is hard because people do not speak in task graphs.
When someone says:
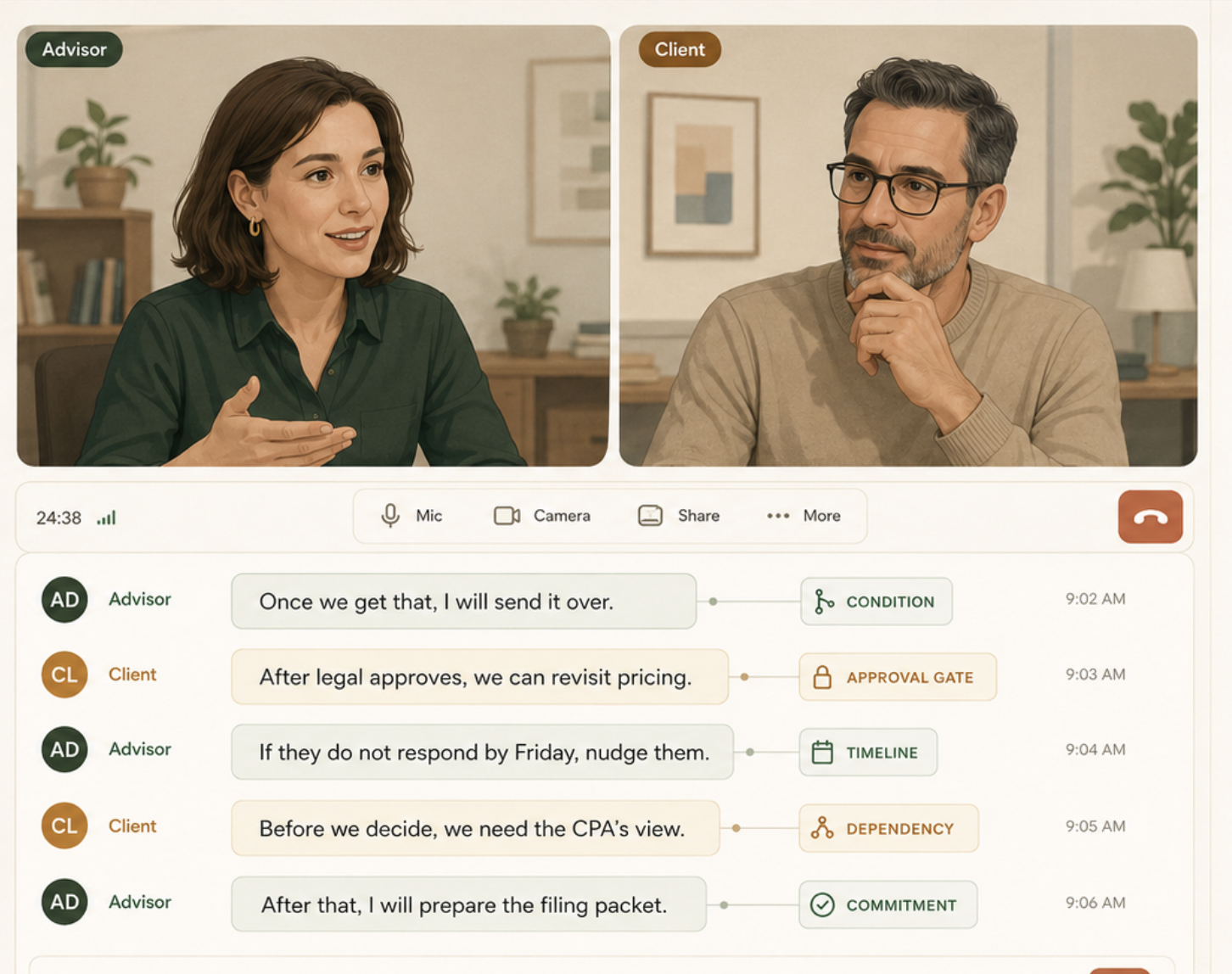
Once we get that, I will send it over.
the agent must resolve:
What is "that"?
What is being sent?
Who is responsible?
What must happen first?
When should the agent check again?
What if "that" never arrives?
What would count as done?
Can the agent send it, or only draft it?
When someone says:
After legal approves, we can revisit pricing.
the agent must understand that this is not a normal calendar reminder. It is an event dependency. The agent should not simply wake on a fixed date. It should wait for evidence that legal approval happened, then bring pricing back into attention.
When someone says:
If they do not respond by Friday, nudge them.
The agent has to preserve a conditional workflow:
wait until Friday
check whether a response arrived
if no response, nudge or draft a nudge depending on permission
if response arrived, close the loop
The operational memory is more than evolving knowledge. It is an executable interpretation.
The Filing Example
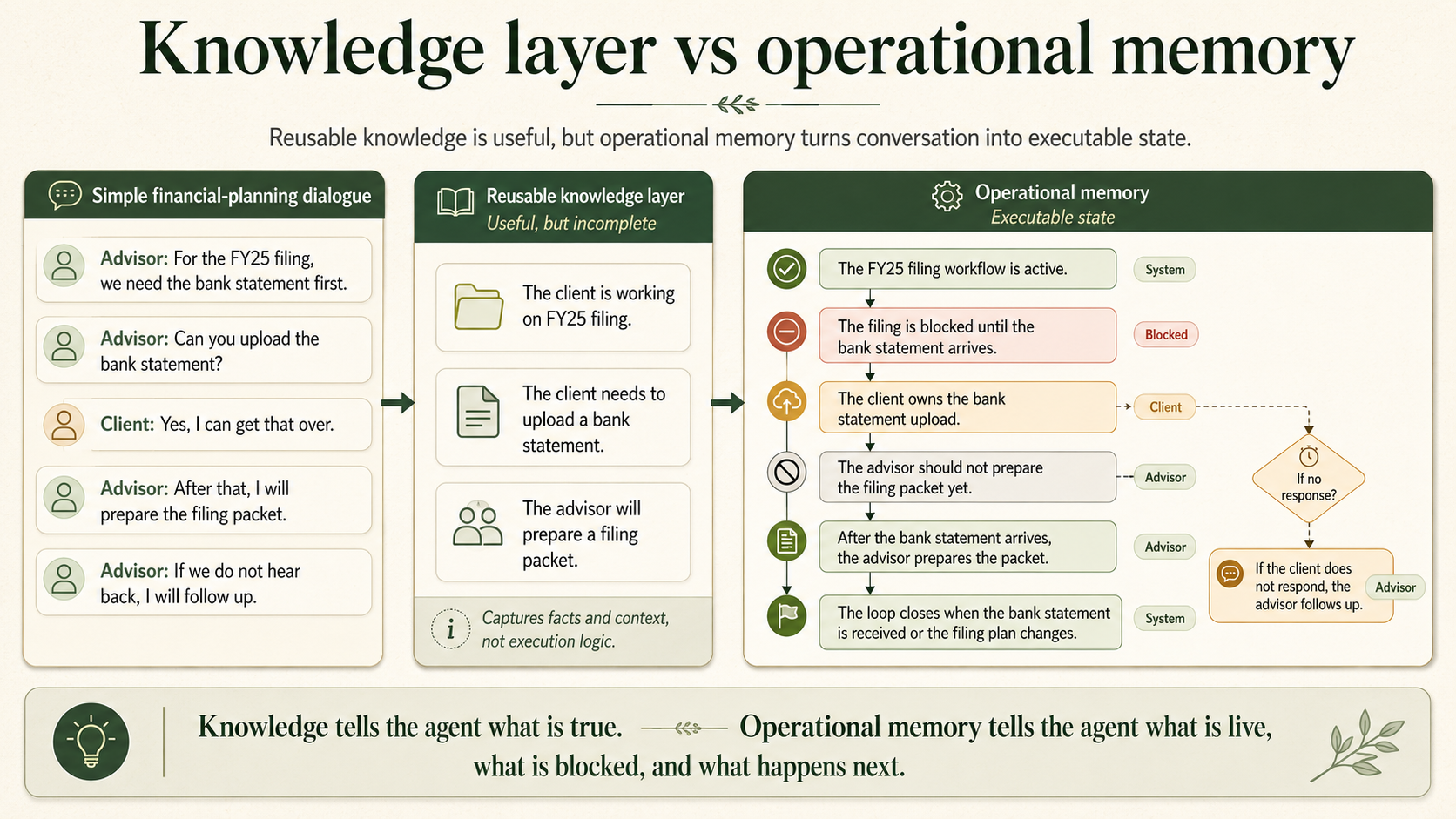
Consider a simple financial-planning dialogue:
Advisor: For the FY25 filing, we need the bank statement first.
Advisor: Can you upload the bank statement?
Client: Yes, I can get that over.
Advisor: After that, I will prepare the filing packet.
Advisor: If we do not hear back, I will follow up.
A reusable knowledge layer might store:
The client is working on FY25 filing.
The client needs to upload a bank statement.
The advisor will prepare a filing packet.
Useful, but incomplete.
Operational memory should store:
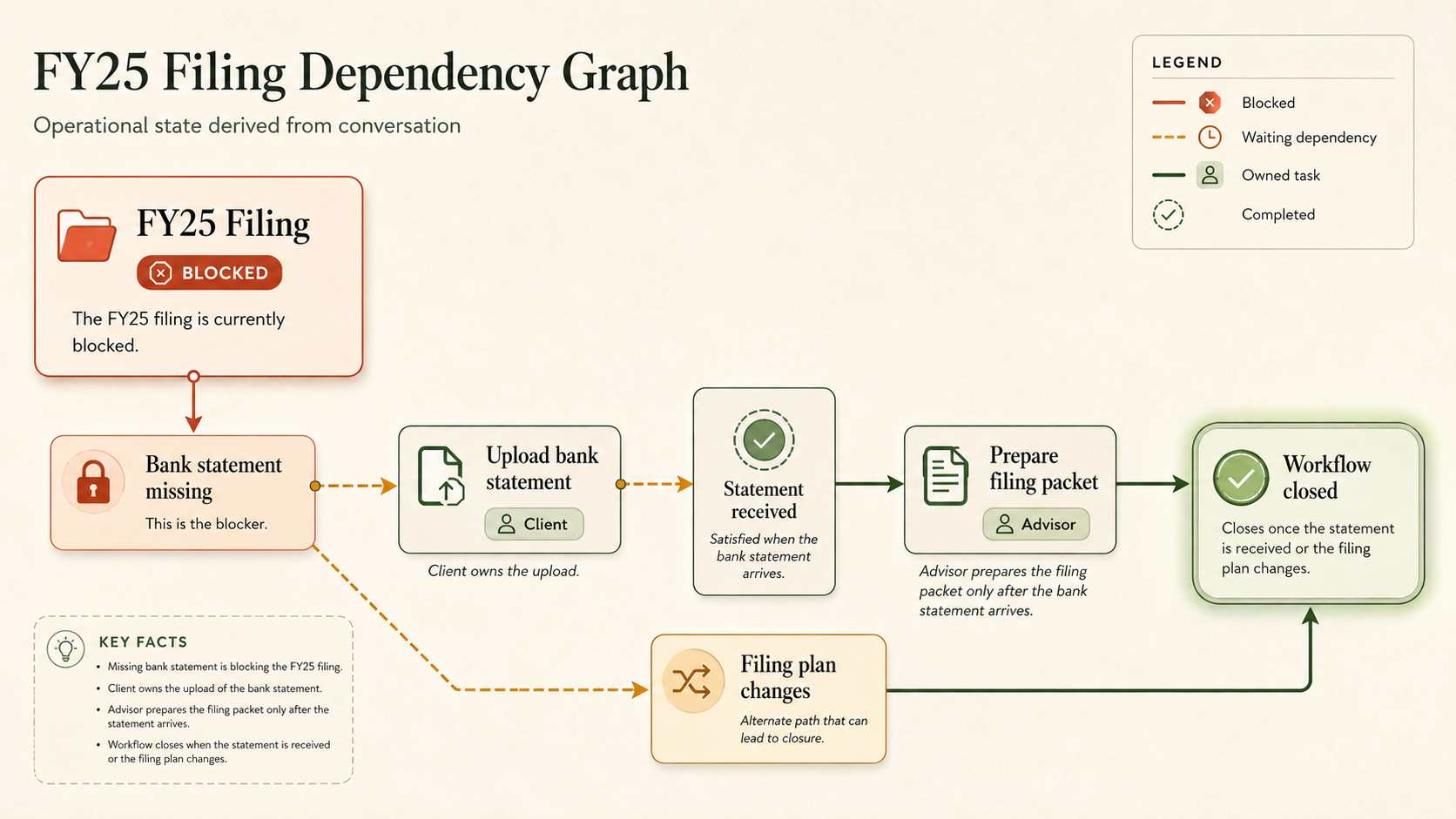
The FY25 filing workflow is active.
The filing is blocked until the bank statement arrives.
The client owns the bank statement upload.
The advisor should not prepare the filing packet yet.
After the bank statement arrives, the advisor prepares the packet.
If the client does not respond, the advisor follows up.
The loop closes when the bank statement is received or the filing plan changes.
One detail matters here: the sentence "If we do not hear back, I will follow up" does not include a date. So the operational memory should not invent one. It should mark the follow-up condition as real, but the timing as missing or needing a default policy.
That is exactly the difference between reusable knowledge and operational memory.
Reusable knowledge can be approximate.
Operational memory must be precise enough to avoid wrong action.
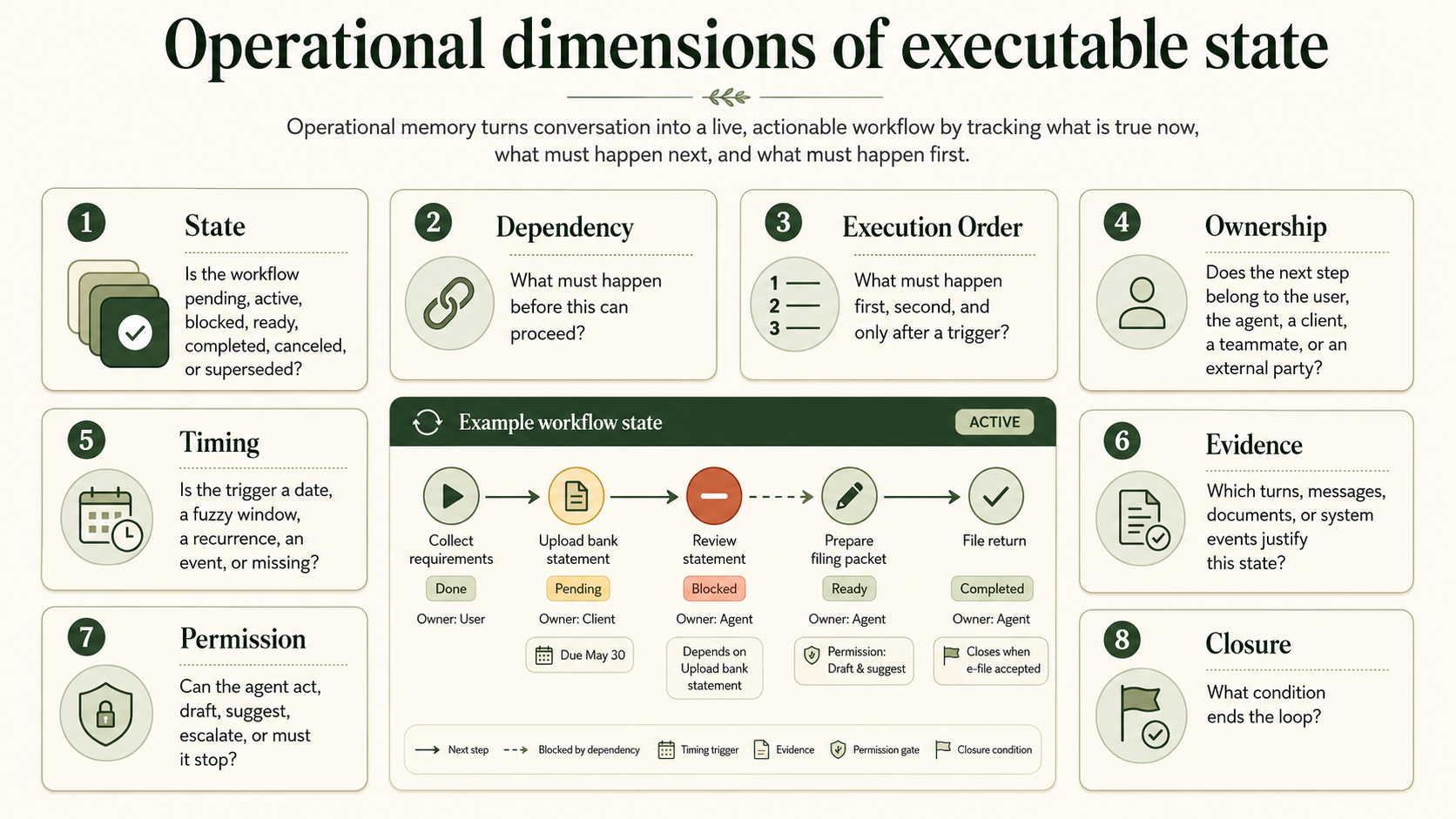
The Eight Pillars
Operational memory needs eight core dimensions.
State: Is the workflow pending, active, blocked, ready, completed, canceled, or superseded?
Dependency: What must happen before this can proceed?
Execution Order: What must happen first, second, and only after a trigger?
Ownership: Does the next step belong to the user, the agent, a client, a teammate, or an external party?
Timing: Is the trigger a date, a fuzzy window, a recurrence, an event, or missing?
Evidence: Which turns, messages, documents, or system events justify this state?
Permission: Can the agent act, draft, suggest, escalate, or must it stop?
Closure: What condition ends the loop?
These fields should not be buried in prose. They need to be structured, queryable, and updateable.
The Architecture Shift
For reactive agents, memory is mostly a retrieval infrastructure.
For proactive agents, memory also becomes execution infrastructure.
That does not mean vector search, reusable knowledge, or context trees disappear. They remain valuable. But they should not be asked to perform the job of operational state.
A practical architecture looks like this:
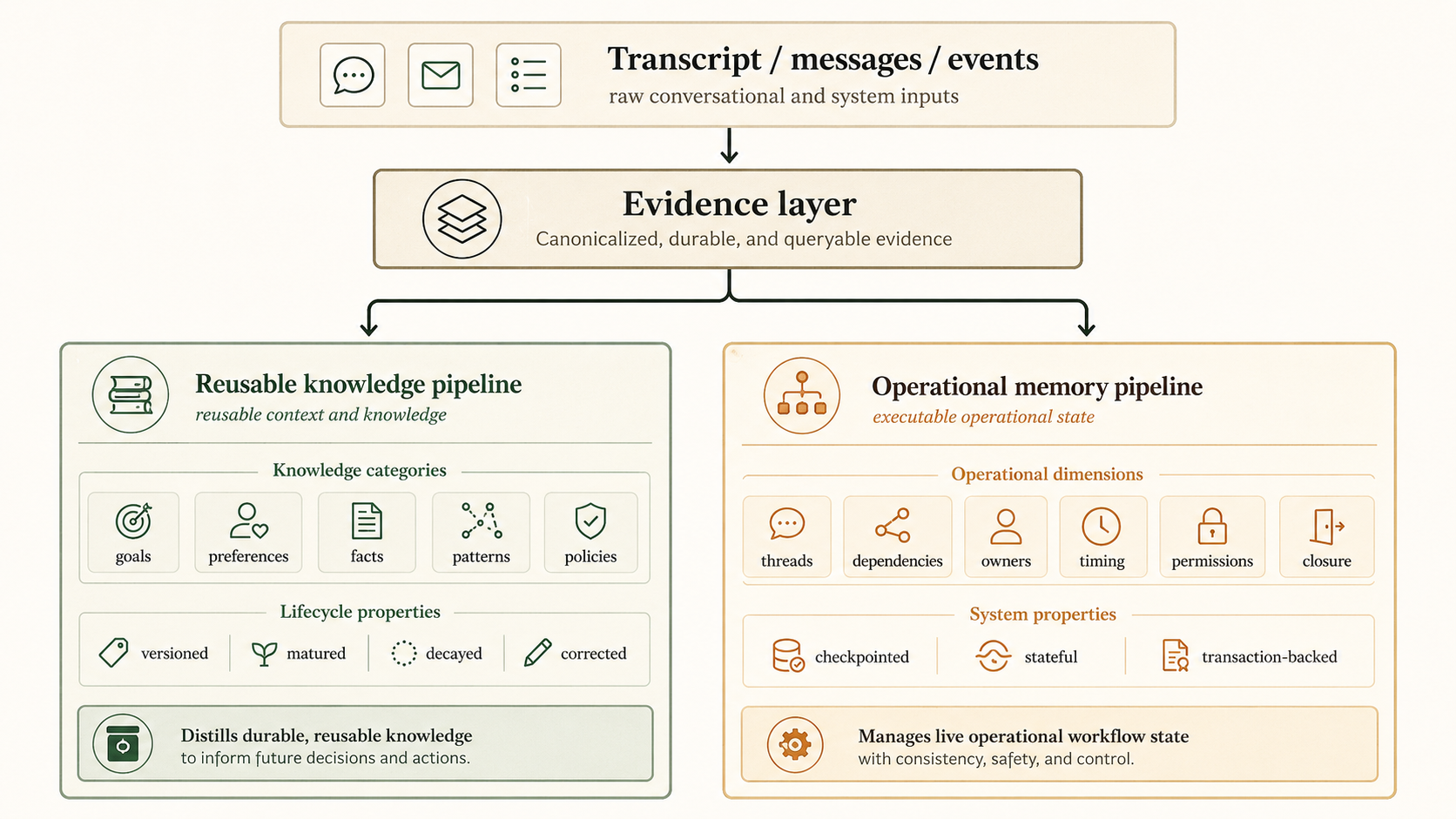
The two pipelines share evidence, but they serve different runtime needs.
A representative operational memory object might look like:
{
"thread": "Collect bank statement for FY25 filing",
"parent_thread": "Complete FY25 filing",
"status": "pending",
"owner": "client",
"relation_to_parent": "blocks",
"evidence_turn_ids": ["turn_01", "turn_02", "turn_03"],
"next_step": "Advisor prepares filing packet after bank statement arrives",
"conditional_follow_up": {
"condition": "client does not respond",
"timing": "missing",
"needs_confirmation": true
},
"permission_boundary": "draft_before_send",
"stop_condition": "Bank statement received or filing plan changes"
}
This object should not just be pasted into a prompt. It should feed the scheduler, the orchestration loop, the permission system, and the audit trail.
The agent can now ask:
Is the dependency resolved?
Is the next step ready?
Is there a valid wake trigger?
Can I act automatically?
Do I need approval?
Has the stop condition already been met?
Those are execution questions, not retrieval questions.
Smart vs. Useful
An agent with strong reusable knowledge can feel smart.
It remembers your preferences. It knows your project. It understands your client history. It can hold a contextual conversation that feels informed.
But when the chat window closes, reusable knowledge alone does not keep work moving. The useful agent needs operational memory. It needs to know what remains open, what is blocked, what comes next, what must wait, and when to stop.
That is the missing distinction.
Reusable knowledge helps agents understand. Operational memory helps agents follow through.
The future of proactive AI will not be built on one universal memory layer. It will be built on memory systems matched to the work they are supposed to do: durable knowledge for understanding, and operational state for execution.