Your AI Agent Telemetry is More Valuable Than You Think: Execution Trajectories and the Dawn of CL/CD

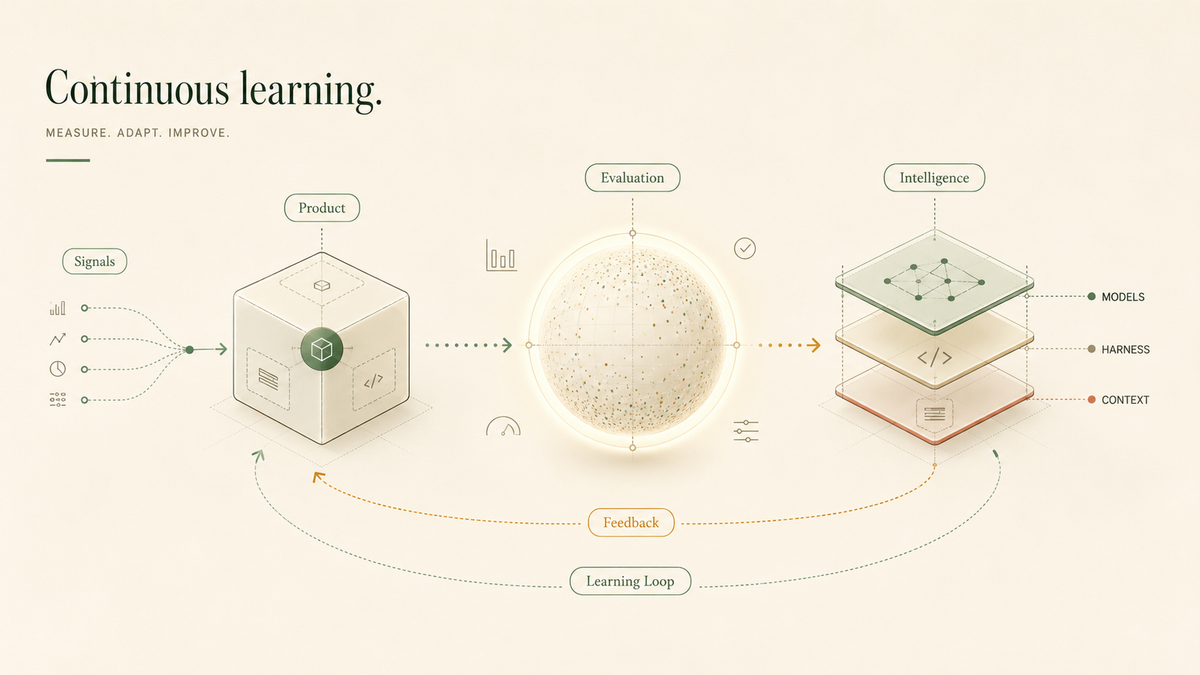
Engineering teams mostly ignore their LLM and agent telemetry by treating it like traditional software logs: a depreciating asset to be discarded.
In the world of legacy software, logging serves primarily as a cost center. We record stack traces and database timeouts to squash bugs, then rely on short retention policies to minimize storage costs, keep them around only for auditing purposes, since their value drastically drops with each passing day.
Unfortunately, this same mindset is being applied to the execution trace AI agents. Traces are scrutinized only during hallucinations or crashes; once resolved, that data is ignored. By equating agent traces with crash logs, organizations are discarding the very dataset needed to break free from the expensive "Frontier-model API tax."
While traditional software relies on CI/CD to deploy static code, the AI era demands CL/CD (Continuous Learning / Continuous Deployment). This new paradigm enables iterative shipping of model behaviors without downtime, fueled entirely by agent telemetry.
What Exactly is an Execution Trajectory?
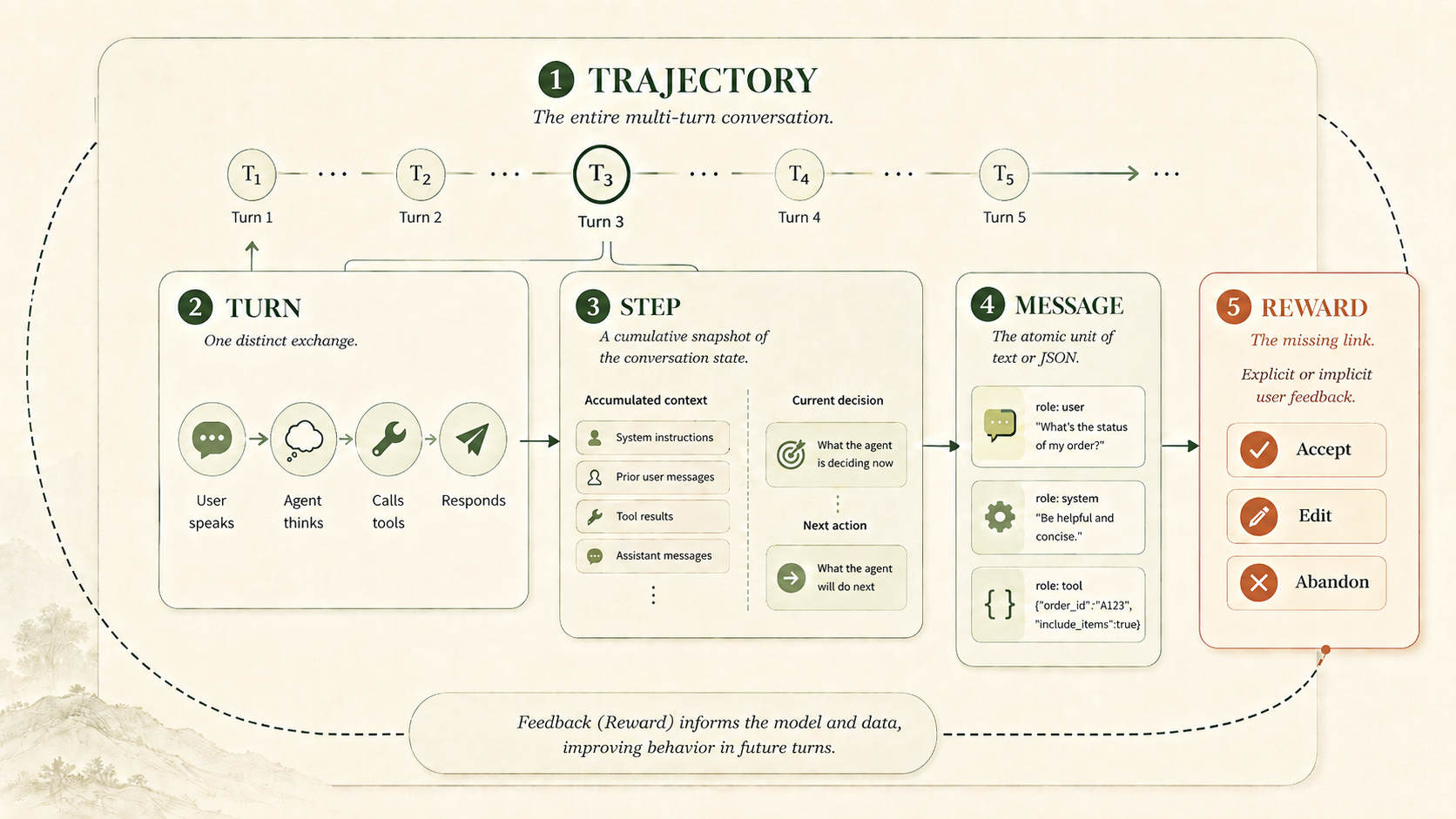
To grasp why discarding telemetry is such a significant strategic mistake, we must examine the specific data contained within an agent's payload. While a traditional software log identifies what failed, an execution trajectory details how the solution was reached and, most importantly, the user's ultimate satisfaction with that outcome.
Execution trajectories are far more than simple text logs of interactions. These trajectories represent a sophisticated, multi-layered hierarchy that maps the entire lifecycle of an agent session:
- The Trajectory: A singular object encompassing the full multi-turn dialogue.
- The Turn: An individual exchange involving user input, agent deliberation, tool execution, and the resulting response.
- The Step: A point-in-time snapshot of the agent's specific decision-making process within a given context.
- The Message: The fundamental components, such as text, system directives, or structured JSON tool parameters.
- The Reward (User Feedback): The conclusive session outcome, whether explicit (like clicking "Accept") or implicit (such as manual edits or page abandonment).
Without capturing the final human outcome, a record of prompts and tool calls is merely an observability log, a collection of hoarded text rather than a functional asset.
Integrating user feedback transforms these static logs into dynamic execution trajectories. By serving as a mathematical reward, this data bridges the gap between a dead trace and a live CL/CD pipeline, preserving the entire lifecycle: the initial user objective, RAG context, internal reasoning, tool execution, and the verified result.
Discarding these trajectories means throwing away highly specialized, domain-specific training examples that were essentially subsidized by a frontier model.
Free RLHF and the End of "Frozen Software."
In the traditional machine learning world, building a dataset meant paying domain experts, like financial advisors, doctors, or lawyers, hundreds of dollars an hour to sit in a UI and grade model outputs. Today, if your application is instrumented correctly, your users are doing this for free.
Every time a user interacts with your agent's output, they are providing a mathematical reward signal. When a financial advisor deletes a hallucinated sentence from a drafted email, hits "regenerate," or manually corrects a CRM tool's output, they are handing you explicit preference data.
There are multiple startups that are making strides in simplifying the entire lifecycle of Continuous learning. Prime Intellect and Trajectory are the notable ones that popped up in my research.
As the platform Trajectory.ai perfectly captures in its manifesto:
Continual learning is the process of training models on the data they generate in production. The model improves from real use rather than from curated approximations of use... The era of frozen software is ending.
When you bind the user's final UI event back to the agent's internal trace, you capture perfectly formatted "rejected" and "chosen" trajectories. This is the exact data required to continuously update your models.
The CL/CD Stack: From Trace to Hot-Swapped LoRA
Here is the exact continuous learning loop you can deploy today to turn observability exhaust into self-hosted, hot-swappable AI:
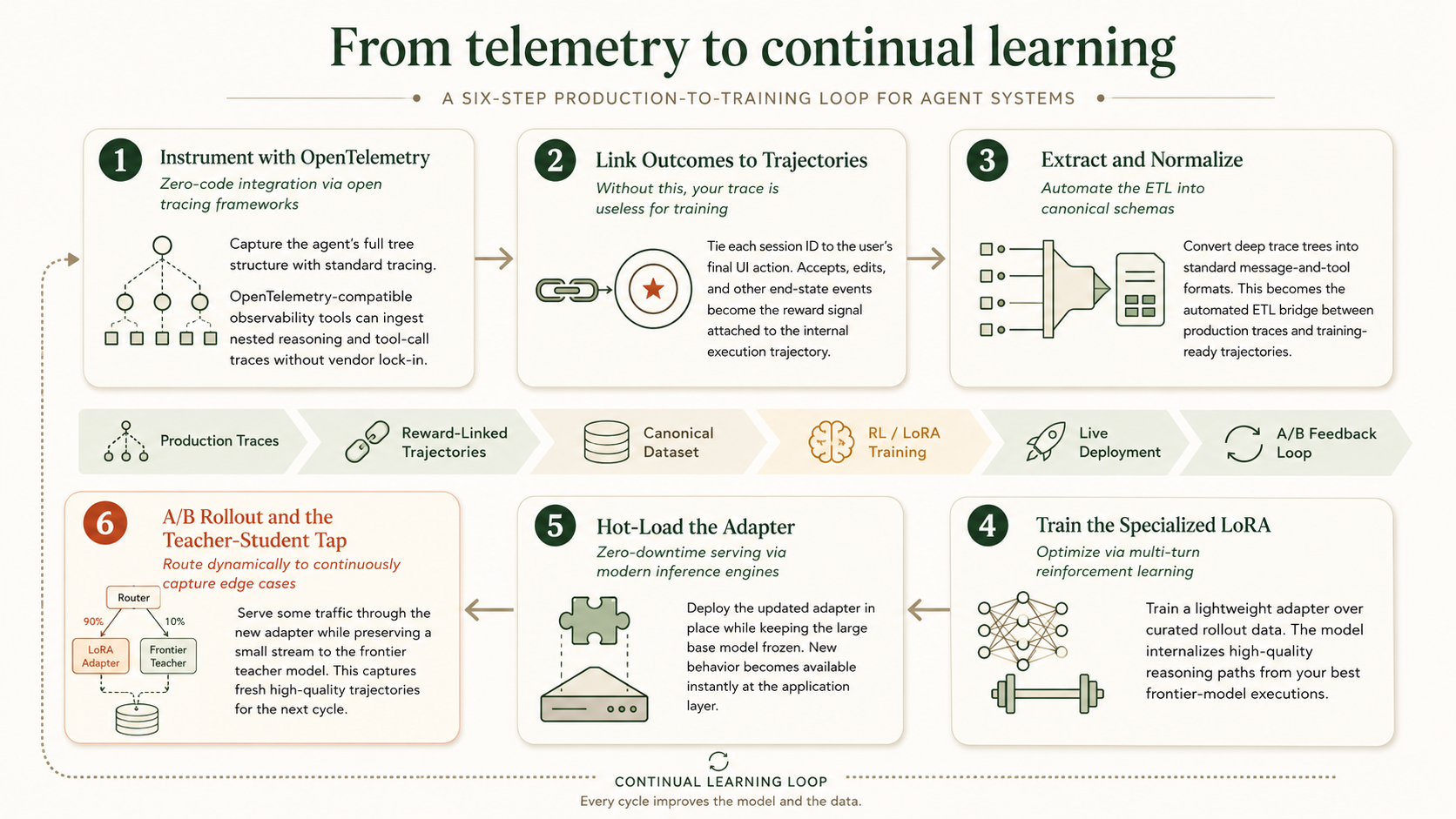
1. Instrument with OpenTelemetry: Zero-code integration via open tracing frameworks.
Stop writing custom JSON loggers. If you use standard orchestration frameworks, capturing your agent's exact tree structure requires zero code changes—just set your environment tracing flags to true (e.g., export LANGSMITH_TRACING=true). For custom Python, drop a @traceable decorator above your functions. Telemetry engines like LangSmith natively intercept the calls, pass trace IDs down the stack, and build a deeply nested JSON hierarchy of your multi-turn reasoning and tool calls. Because the industry is converging on OpenTelemetry GenAI semantic conventions, these platforms allow you to ingest standard OTel traces, guaranteeing flexibility without vendor lock-in.
2. Link Outcomes to Trajectories: Without this, your trace is useless for training.
Ensure your session IDs explicitly link the agent's internal loop to the user's final action in your application's UI. Did they click "accept"? Did they edit the drafted JSON? That final UI event is your required mathematical reward signal.
3. Extract and Normalize: Automate the ETL into canonical schemas.
You don't need to write custom parsers. Observability platforms provide pre-built dataset transformations to automatically extract LLM interactions from your deep state trees into standard message-and-tool formats. Continual learning platforms programmatically ingest these traces and convert them into canonical training trajectories, serving as the automated ETL layer between production and training.
4. Train the Specialized LoRA: Optimize via multi-turn reinforcement learning.
Feed your curated dataset into an open-source Reinforcement Learning framework. Instead of prompt-engineering a frontier model to stop hallucinating, apply RL algorithms (like GRPO) over those exact agentic rollouts. This lets you train a lightweight LoRA adapter on a smaller, highly efficient open-weight model to perfectly internalize the reasoning paths of your best frontier model runs.
5. Hot-Load the Adapter: Zero-downtime serving via modern inference engines.
Once your training loop outputs the updated adapter weights, your inference engine hot-loads them in place. The massive base model remains untouched and frozen in VRAM, while the new behavior is served instantly to your application layer.
6.A/B Rollout and the Teacher-Student Tap: Route dynamically to continuously capture edge cases.
Do not flip the switch all at once. Use an A/B or canary rollout strategy: serve a portion of your traffic with your newly trained LoRA adapter, gradually turning up the tap as confidence in the small model increases. Crucially, always keep a small percentage of requests routing to the frontier model. This ensures your "teacher" model never stops capturing high-quality execution trajectories on new edge cases to feed the next cycle of your CL/CD loop.
The Frontier is a Teacher, Not a Crutch
It is time for a reality check: while frontier models are technical marvels, they represent massive overkill for the vast majority of production workflows.
When your tasks are repeatable and well-defined, whether that involves mapping data to schemas, extracting fields from meetings, or routing compliance tickets, you don’t require a trillion-parameter generalist. What you actually need is a highly specialized, cost-efficient, and rapid engine.
Integrating agent telemetry into a CL/CD pipeline changes the role of the frontier model. It is no longer your primary execution engine; instead, it becomes your data generator. In this teacher-student dynamic, the frontier model provides the golden execution trajectories that your internal, open-source models internalize. Through multi-adapter pipelines, these smaller models become faster, cheaper, and more effective with every iteration.
True defensibility in the AI layer comes from a proprietary dataset of domain-specific execution trajectories linked to verified human outcomes. You are already funding the creation of this asset with every agent run. Stop treating this data as digital exhaust and start using it to fuel your CL/CD engine!